Chapter 2 Dependency on the parameter \(\sigma^2\)
In this section, we will focus on the dependency of the results from the previous Chapter 1 on the value of \(\sigma^2\), which defines the variance of the normal distribution from which we generate random errors around the generating curves (we can say that \(\sigma^2\) carries information about the measurement error of a certain device, for example). We expect that with an increasing value of \(\sigma^2\), the results of the individual methods will deteriorate, and thus classification will not be as successful. In the following section 3, we will then examine the dependency of the results on the value of \(\sigma^2_{shift}\), that is, the variance of the normal distribution from which we generate the shift for the generated curves.
2.1 Simulation of Functional Data
First, we will simulate the functions that we will later want to classify. For simplicity, we will consider two classification classes. For the simulation, we will first:
choose appropriate functions,
generate points from the chosen interval, which contain, for example, Gaussian noise,
smooth the obtained discrete points into the form of a functional object using some suitable basis system.
Through this procedure, we will obtain functional objects along with the value of the categorical variable \(Y\), which distinguishes the belonging to a classification class.
Code
Let us consider two classification classes, \(Y \in \{0, 1\}\), with the same number of generated functions n for each class. First, we will define two functions, each for one class. We will consider the functions over the interval \(I = [0, 6]\).
Now we will create functions using interpolation polynomials. First, we will define the points through which our curve should pass, and then we will interpolate them with a polynomial, which we will use to generate curves for classification.
Code
# Defining points for class 0
x.0 <- c(0.00, 0.65, 0.94, 1.42, 2.26, 2.84, 3.73, 4.50, 5.43, 6.00)
y.0 <- c(0, 0.25, 0.86, 1.49, 1.1, 0.15, -0.11, -0.36, 0.23, 0)
# Defining points for class 1
x.1 <- c(0.00, 0.51, 0.91, 1.25, 1.51, 2.14, 2.43, 2.96, 3.70, 4.60,
5.25, 5.67, 6.00)
y.1 <- c(0.1, 0.4, 0.71, 1.08, 1.47, 1.39, 0.81, 0.05, -0.1, -0.4,
0.3, 0.37, 0)Code
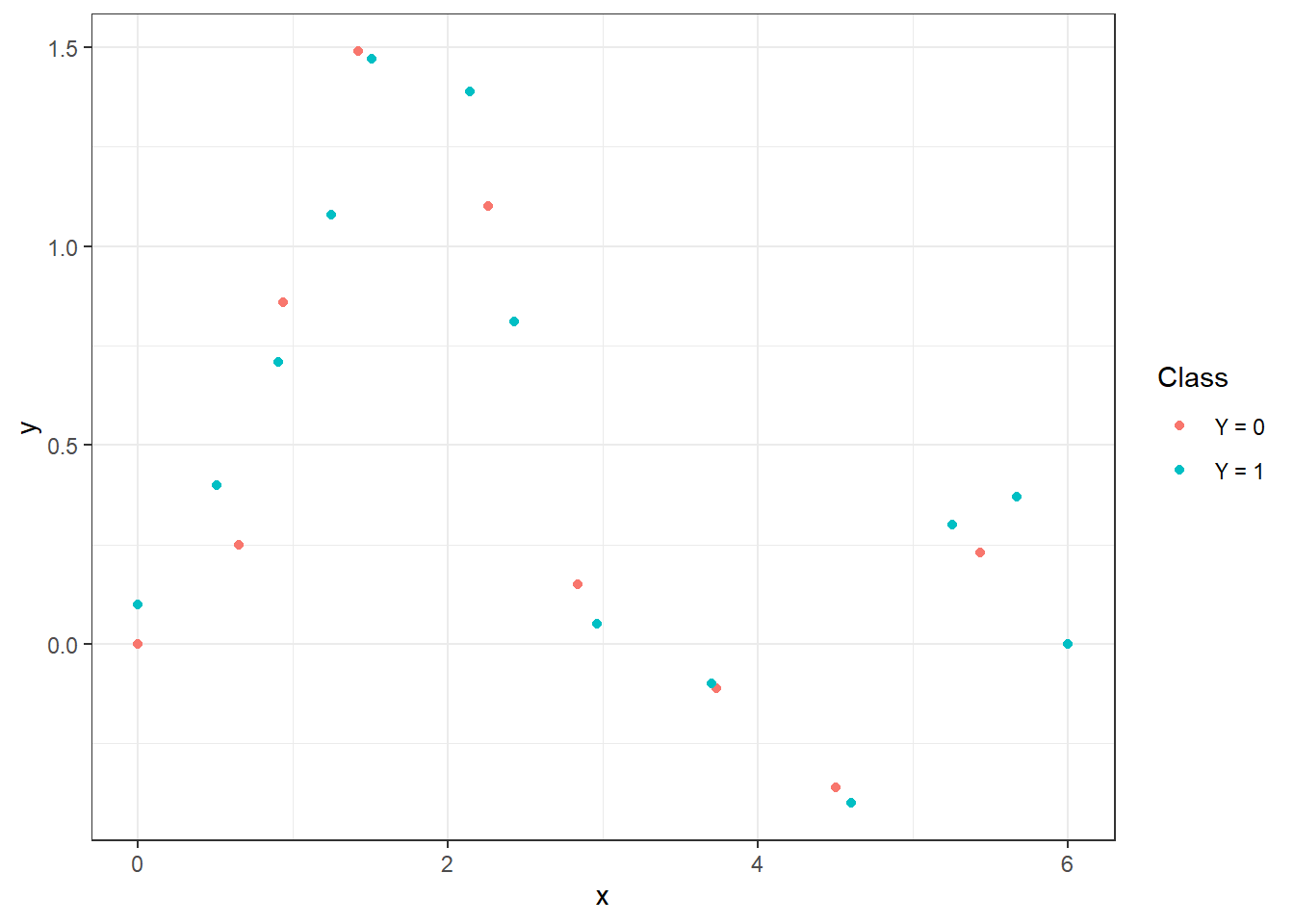
Figure 1.1: Body defining interpolation polynomials.
To calculate the interpolation polynomials, we will use the function poly.calc() from the polynom package. We will also define the functions poly.0() and poly.1(), which will calculate the values of the polynomials at a given point in the interval. We will use the function predict(), to which we will input the corresponding polynomial and the point at which we want to evaluate the polynomial.
Code
Code
# Plotting polynomials
xx <- seq(min(x.0), max(x.0), length = 501)
yy.0 <- poly.0(xx)
yy.1 <- poly.1(xx)
dat_poly_plot <- data.frame(x = c(xx, xx),
y = c(yy.0, yy.1),
Class = rep(c('Y = 0', 'Y = 1'),
c(length(xx), length(xx))))
ggplot(dat_points, aes(x = x, y = y, colour = Class)) +
geom_point(size=1.5) +
theme_bw() +
geom_line(data = dat_poly_plot,
aes(x = x, y = y, colour = Class),
linewidth = 0.8) +
labs(colour = 'Class')![Illustration of two functions over the interval $I = [0, 6]$, from which we generate observations from classes 0 and 1.](02-Simulace_sigma_files/figure-html/unnamed-chunk-6-1.png)
Figure 1.2: Illustration of two functions over the interval \(I = [0, 6]\), from which we generate observations from classes 0 and 1.
Now we will create a function for generating random functions with added noise (or points on a predetermined grid) from the chosen generating function. The argument t denotes the vector of values at which we want to evaluate the functions, fun indicates the generating function, n is the number of functions, and sigma is the standard deviation \(\sigma\) of the normal distribution \(\text{N}(\mu, \sigma^2)\), from which we randomly generate Gaussian white noise with \(\mu = 0\). To demonstrate the advantage of using methods that work with functional data, we will also add a random component to each simulated observation, which will represent the vertical shift of the entire function (parameter sigma_shift). This shift will be generated from a normal distribution with the parameter \(\sigma^2 = 4\).
Code
generate_values <- function(t, fun, n, sigma, sigma_shift = 0) {
# Arguments:
# t ... vector of values, where the function will be evaluated
# fun ... generating function of t
# n ... the number of generated functions / objects
# sigma ... standard deviation of normal distribution to add noise to data
# sigma_shift ... parameter of normal distribution for generating shift
# Value:
# X ... matrix of dimension length(t) times n with generated values of one
# function in a column
X <- matrix(rep(t, times = n), ncol = n, nrow = length(t), byrow = FALSE)
noise <- matrix(rnorm(n * length(t), mean = 0, sd = sigma),
ncol = n, nrow = length(t), byrow = FALSE)
shift <- matrix(rep(rnorm(n, 0, sigma_shift), each = length(t)),
ncol = n, nrow = length(t))
return(fun(X) + noise + shift)
}Now we can generate functions. In each of the two classes, we will consider 100 observations, thus n = 100.
Code
We will plot the generated (not smoothed) functions colored by class (only the first 10 observations from each class for clarity).
Code
n_curves_plot <- 10 # number of curves to plot from each group
DF0 <- cbind(t, X0[, 1:n_curves_plot]) |>
as.data.frame() |>
reshape(varying = 2:(n_curves_plot + 1), direction = 'long', sep = '') |>
subset(select = -id) |>
mutate(
time = time - 1,
group = 0
)
DF1 <- cbind(t, X1[, 1:n_curves_plot]) |>
as.data.frame() |>
reshape(varying = 2:(n_curves_plot + 1), direction = 'long', sep = '') |>
subset(select = -id) |>
mutate(
time = time - 1,
group = 1
)
DF <- rbind(DF0, DF1) |>
mutate(group = factor(group))
DF |> ggplot(aes(x = t, y = V, group = interaction(time, group),
colour = group)) +
geom_line(linewidth = 0.5) +
theme_bw() +
labs(x = expression(x[1]),
y = expression(x[2]),
colour = 'Class') +
scale_colour_discrete(labels=c('Y = 0', 'Y = 1'))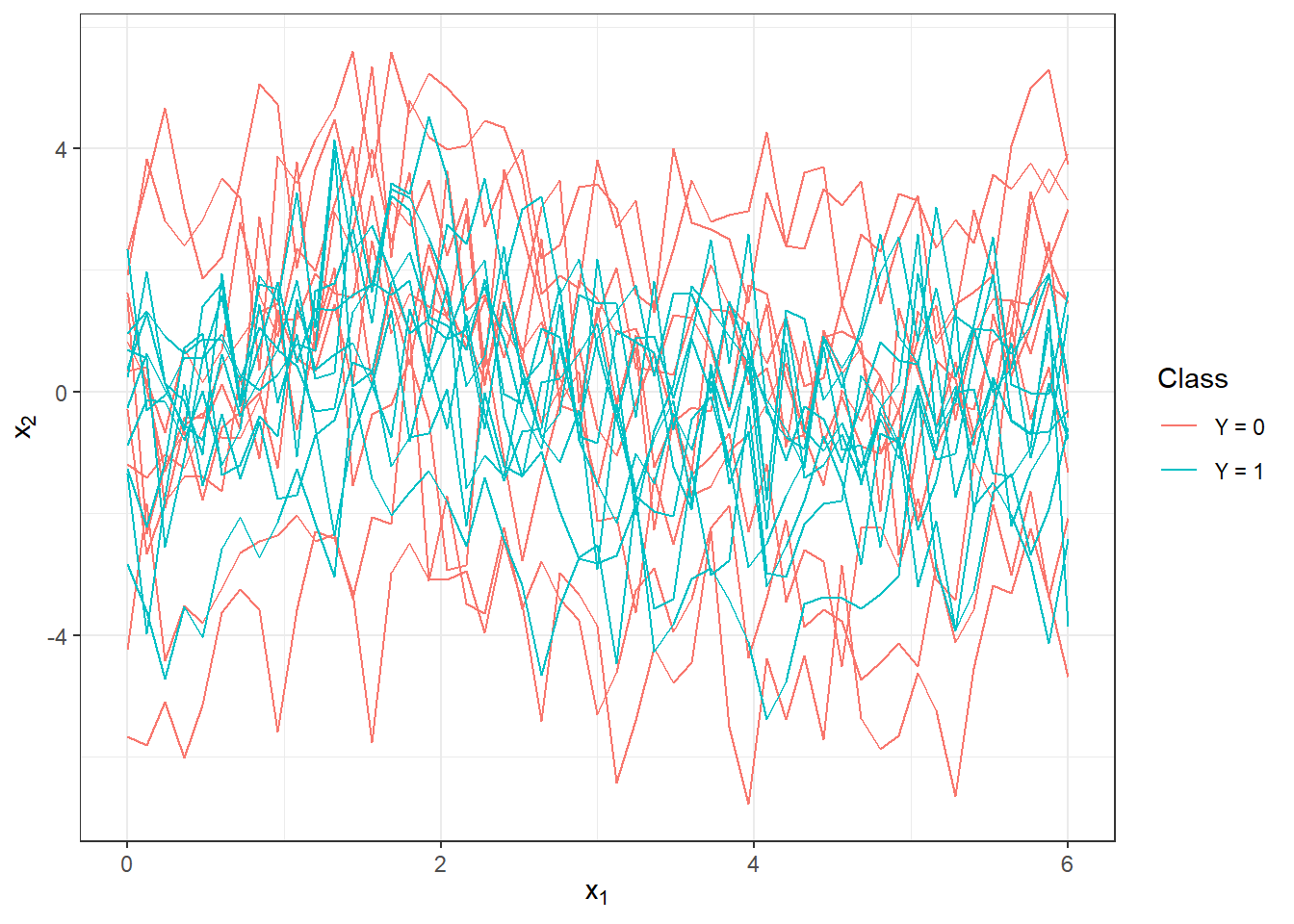
Figure 2.1: First 10 generated observations from each of the two classification classes. The observed data are not smoothed.
2.2 Smoothing the Observed Curves
Now we will convert the observed discrete values (vectors of values) into functional objects that we will subsequently work with. We will again use B-spline basis for smoothing.
We take the entire vector t as the knots, and we typically consider cubic splines, thus we choose (the implicit choice in R) norder = 4. We will penalize the second derivative of the functions.
Code
We will find an appropriate value of the smoothing parameter \(\lambda > 0\) using \(GCV(\lambda)\), that is, using generalized cross-validation. We will consider the value of \(\lambda\) the same for both classification groups, since for test observations, we would not know in advance which value of \(\lambda\), in the case of different choices for each class, we should select.
Code
# combining observations into one matrix
XX <- cbind(X0, X1)
lambda.vect <- 10^seq(from = -2, to = 1, length.out = 50) # vector of lambdas
gcv <- rep(NA, length = length(lambda.vect)) # empty vector for storing GCV
for(index in 1:length(lambda.vect)) {
curv.Fdpar <- fdPar(bbasis, curv.Lfd, lambda.vect[index])
BSmooth <- smooth.basis(t, XX, curv.Fdpar) # smoothing
gcv[index] <- mean(BSmooth$gcv) # average over all observed curves
}
GCV <- data.frame(
lambda = round(log10(lambda.vect), 3),
GCV = gcv
)
# find the minimum value
lambda.opt <- lambda.vect[which.min(gcv)]For better visualization, we will plot the progression of \(GCV(\lambda)\).
Code
GCV |> ggplot(aes(x = lambda, y = GCV)) +
geom_line(linetype = 'solid', linewidth = 0.6) +
geom_point(size = 1.5) +
theme_bw() +
labs(x = bquote(paste(log[10](lambda), ' ; ',
lambda[optimal] == .(round(lambda.opt, 4)))),
y = expression(GCV(lambda))) +
geom_point(aes(x = log10(lambda.opt), y = min(gcv)), colour = 'red', size = 2.5)## Warning in geom_point(aes(x = log10(lambda.opt), y = min(gcv)), colour = "red", : All aesthetics have length 1, but the data has 50 rows.
## ℹ Please consider using `annotate()` or provide this layer with data containing
## a single row.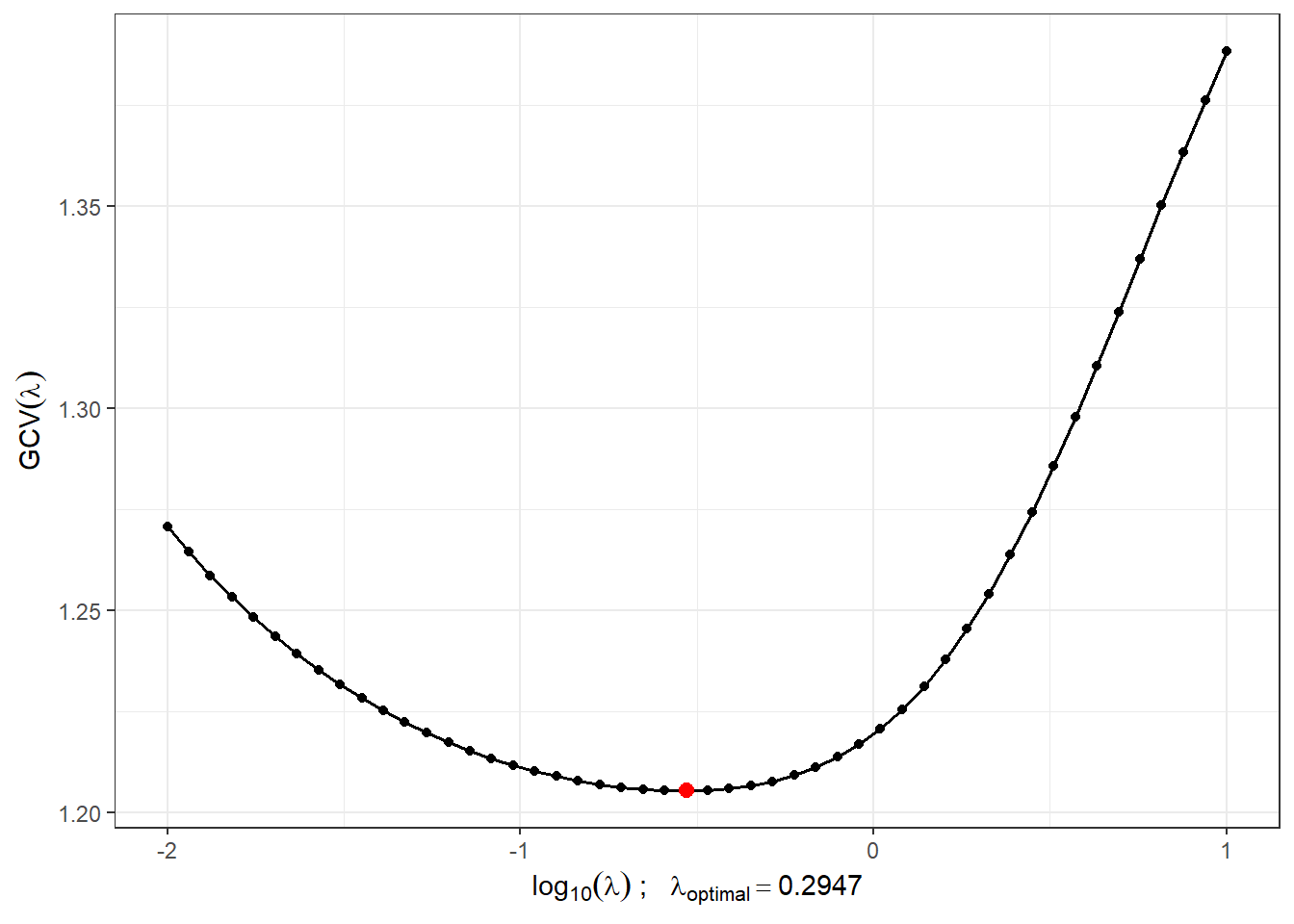
Figure 1.5: The progression of \(GCV(\lambda)\) for the chosen vector \(\boldsymbol\lambda\). The values on the x-axis are plotted on a logarithmic scale. The optimal value of the smoothing parameter \(\lambda_{optimal}\) is shown in red.
With this optimal choice of the smoothing parameter \(\lambda\), we will now smooth all functions and again graphically represent the first 10 observed curves from each classification class.
Code
curv.fdPar <- fdPar(bbasis, curv.Lfd, lambda.opt)
BSmooth <- smooth.basis(t, XX, curv.fdPar)
XXfd <- BSmooth$fd
fdobjSmootheval <- eval.fd(fdobj = XXfd, evalarg = t)
DF$Vsmooth <- c(fdobjSmootheval[, c(1 : n_curves_plot,
(n + 1) : (n + n_curves_plot))])
DF |> ggplot(aes(x = t, y = Vsmooth, group = interaction(time, group),
colour = group)) +
geom_line(linewidth = 0.75) +
theme_bw() +
labs(x = expression(x[1]),
y = expression(x[2]),
colour = 'Class') +
scale_colour_discrete(labels=c('Y = 0', 'Y = 1'))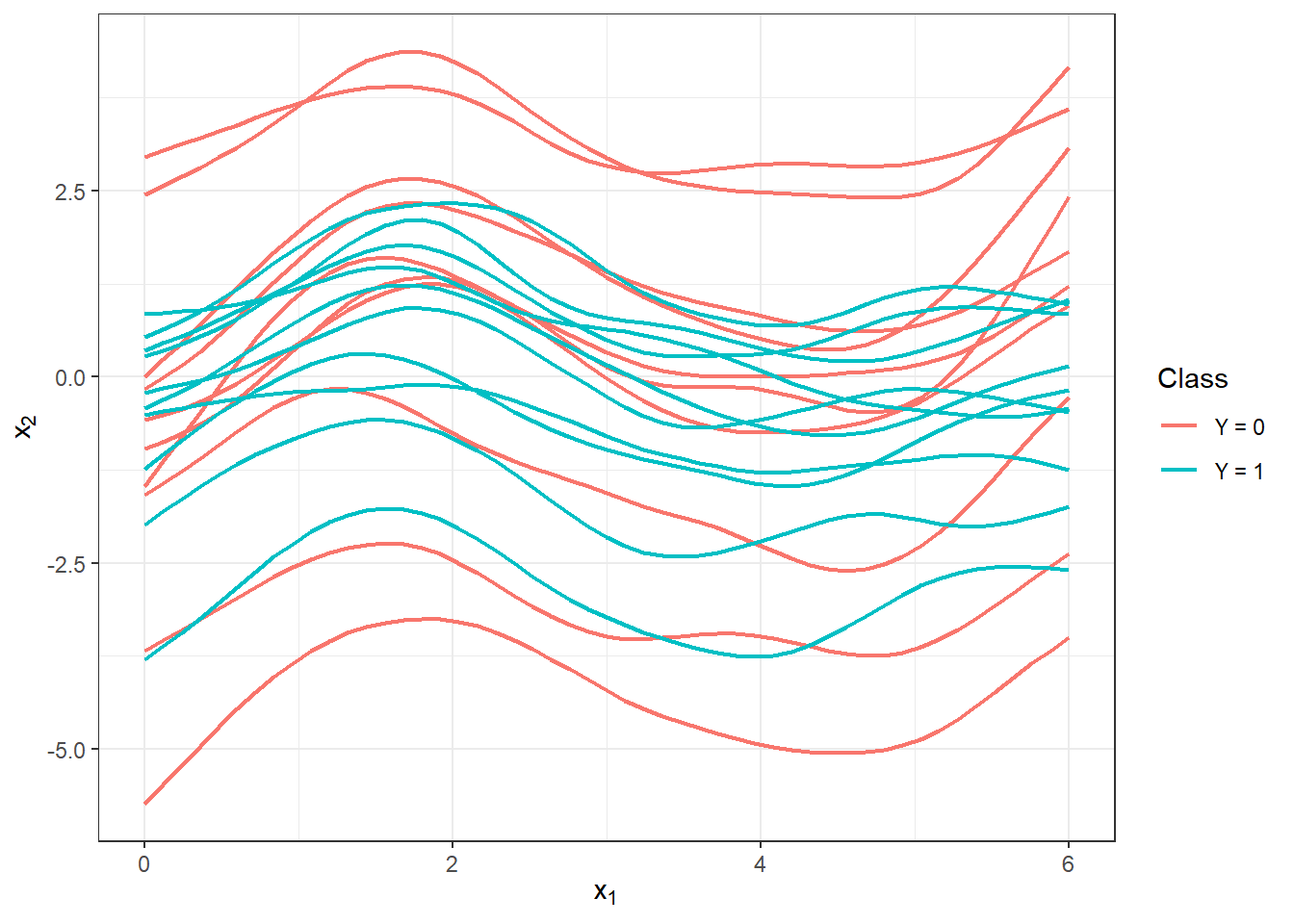
Figure 1.6: First 10 smoothed curves from each classification class.
Let’s also visualize all curves, including the average, separately for each class.
Code
DFsmooth <- data.frame(
t = rep(t, 2 * n),
time = rep(rep(1:n, each = length(t)), 2),
Smooth = c(fdobjSmootheval),
Mean = c(rep(apply(fdobjSmootheval[ , 1 : n], 1, mean), n),
rep(apply(fdobjSmootheval[ , (n + 1) : (2 * n)], 1, mean), n)),
group = factor(rep(c(0, 1), each = n * length(t)))
)
DFmean <- data.frame(
t = rep(t, 2),
Mean = c(apply(fdobjSmootheval[ , 1 : n], 1, mean),
apply(fdobjSmootheval[ , (n + 1) : (2 * n)], 1, mean)),
group = factor(rep(c(0, 1), each = length(t)))
)
DFsmooth |> ggplot(aes(x = t, y = Smooth, group = interaction(time, group),
colour = group)) +
geom_line(linewidth = 0.25, alpha = 0.5) +
theme_bw() +
labs(x = expression(x[1]),
y = expression(x[2]),
colour = 'Class') +
scale_colour_discrete(labels = c('Y = 0', 'Y = 1')) +
geom_line(aes(x = t, y = Mean, colour = group),
linewidth = 1.2, linetype = 'solid') +
scale_x_continuous(expand = c(0.01, 0.01)) +
#ylim(c(-1, 2)) +
scale_y_continuous(expand = c(0.01, 0.01))#, limits = c(-1, 2))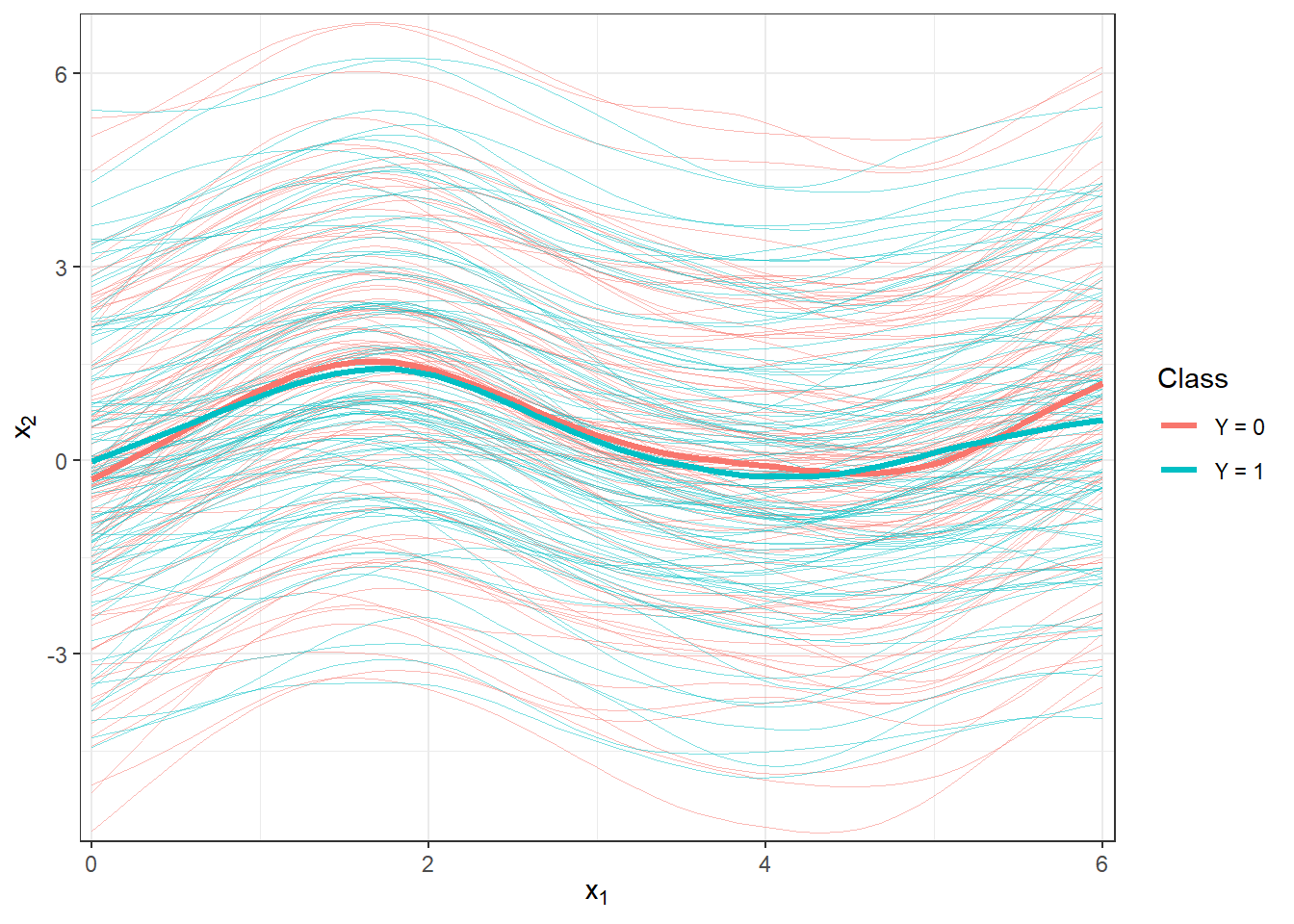
Figure 1.7: Plotting all smoothed observed curves, with colors distinguishing the curves by their classification class. The thick line represents the average for each class.
Code
DFsmooth <- data.frame(
t = rep(t, 2 * n),
time = rep(rep(1:n, each = length(t)), 2),
Smooth = c(fdobjSmootheval),
Mean = c(rep(apply(fdobjSmootheval[ , 1 : n], 1, mean), n),
rep(apply(fdobjSmootheval[ , (n + 1) : (2 * n)], 1, mean), n)),
group = factor(rep(c(0, 1), each = n * length(t)))
)
DFmean <- data.frame(
t = rep(t, 2),
Mean = c(apply(fdobjSmootheval[ , 1 : n], 1, mean),
apply(fdobjSmootheval[ , (n + 1) : (2 * n)], 1, mean)),
group = factor(rep(c(0, 1), each = length(t)))
)
DFsmooth |> ggplot(aes(x = t, y = Smooth, group = interaction(time, group),
colour = group)) +
geom_line(linewidth = 0.25, alpha = 0.5) +
theme_bw() +
labs(x = expression(x[1]),
y = expression(x[2]),
colour = 'Class') +
scale_colour_discrete(labels = c('Y = 0', 'Y = 1')) +
geom_line(aes(x = t, y = Mean, colour = group),
linewidth = 1.2, linetype = 'solid') +
scale_x_continuous(expand = c(0.01, 0.01)) +
#ylim(c(-1, 2)) +
scale_y_continuous(expand = c(0.01, 0.01), limits = c(-1, 2))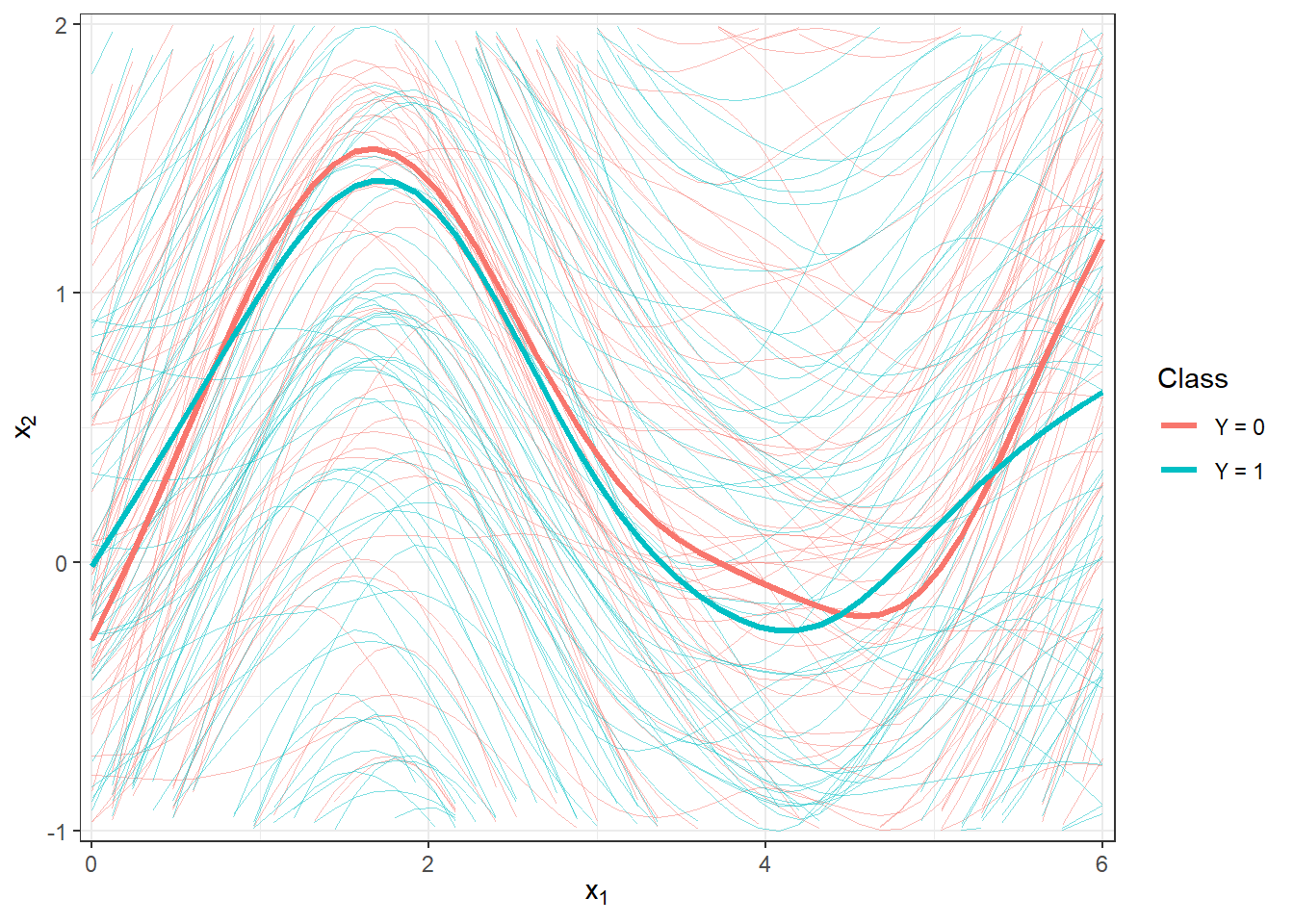
Figure 2.2: Plotting all smoothed observed curves, with colors distinguishing the curves by their classification class. The thick line represents the average for each class. A close-up view.
2.3 Classification of Curves
First, we will load the necessary libraries for classification.
Code
library(caTools) # for splitting into test and training
library(caret) # for k-fold CV
library(fda.usc) # for KNN, fLR
library(MASS) # for LDA
library(fdapace)
library(pracma)
library(refund) # for LR on scores
library(nnet) # for LR on scores
library(caret)
library(rpart) # trees
library(rattle) # graphics
library(e1071)
library(randomForest) # random forestTo compare individual classifiers, we will divide the generated observations into two parts in a ratio of 70:30, specifically for training and testing (validation) purposes. The training part will be used in constructing the classifier, while the testing part will be used for calculating the classification error and potentially other characteristics of our model. The resulting classifiers can then be compared against each other based on their classification success according to these calculated characteristics.
Code
Next, we will look at the representation of individual groups in the testing and training parts of the data.
## Y.train
## 0 1
## 71 69## Y.test
## 0 1
## 29 31## Y.train
## 0 1
## 0.5071429 0.4928571## Y.test
## 0 1
## 0.4833333 0.51666672.3.1 \(K\) Nearest Neighbors
Let’s start with a non-parametric classification method, the \(K\) nearest neighbors method. First, we will create the necessary objects so that we can further work with them using the classif.knn() function from the fda.usc library.
Now we can define the model and look at its classification success. However, the last question remains how to choose the optimal number of neighbors \(K\). We could choose this number as such \(K\) at which the minimum error occurs on the training data. However, this could lead to model overfitting, so we will use cross-validation. Given the computational intensity and the size of the dataset, we will choose \(k\)-fold CV, for example, selecting the value \(k = 10\).
Code
# model for all training data for K = 1, 2, ..., sqrt(n_train)
neighb.model <- classif.knn(group = y.train,
fdataobj = x.train,
knn = c(1:round(sqrt(length(y.train)))))
# summary(neighb.model) # model summary
# plot(neighb.model$gcv, pch = 16) # plot of GCV dependence on the number of neighbors K
# neighb.model$max.prob # maximum accuracy
(K.opt <- neighb.model$h.opt) # optimal value of K## [1] 5Let’s repeat the previous procedure for the training data, which we will divide into \(k\) parts, thus repeating this part of the code \(k\) times.
Code
k_cv <- 10 # k-fold CV
neighbours <- c(1:(2 * ceiling(sqrt(length(y.train))))) # number of neighbors
# divide training data into k parts
folds <- createMultiFolds(X.train$fdnames$reps, k = k_cv, time = 1)
# empty matrix where we will insert individual results
# the columns will contain accuracy values for the given part of the training set
# the rows will contain values for the given value of K
CV.results <- matrix(NA, nrow = length(neighbours), ncol = k_cv)
for (index in 1:k_cv) {
# define the specific index set
fold <- folds[[index]]
x.train.cv <- subset(X.train, c(1:length(X.train$fdnames$reps)) %in% fold) |>
fdata()
y.train.cv <- subset(Y.train, c(1:length(X.train$fdnames$reps)) %in% fold) |>
factor() |> as.numeric()
x.test.cv <- subset(X.train, !c(1:length(X.train$fdnames$reps)) %in% fold) |>
fdata()
y.test.cv <- subset(Y.train, !c(1:length(X.train$fdnames$reps)) %in% fold) |>
factor() |> as.numeric()
# go through each part ... repeat k times
for(neighbour in neighbours) {
# model for specific choice of K
neighb.model <- classif.knn(group = y.train.cv,
fdataobj = x.train.cv,
knn = neighbour)
# predictions on the validation part
model.neighb.predict <- predict(neighb.model,
new.fdataobj = x.test.cv)
# accuracy on the validation part
accuracy <- table(y.test.cv, model.neighb.predict) |>
prop.table() |> diag() |> sum()
# insert accuracy at the position for the given K and fold
CV.results[neighbour, index] <- accuracy
}
}
# calculate average accuracies for individual K across folds
CV.results <- apply(CV.results, 1, mean)
K.opt <- which.max(CV.results)
accuracy.opt.cv <- max(CV.results)
# CV.resultsWe can see that the best value of the parameter \(K\) is 5 with an error calculated using 10-fold CV of 0.3429. For clarity, let’s also plot the validation error as a function of the number of neighbors \(K\).
Code
CV.results <- data.frame(K = neighbours, CV = CV.results)
CV.results |> ggplot(aes(x = K, y = 1 - CV)) +
geom_line(linetype = 'dashed', colour = 'grey') +
geom_point(size = 1.5) +
geom_point(aes(x = K.opt, y = 1 - accuracy.opt.cv), colour = 'red', size = 2) +
theme_bw() +
labs(x = bquote(paste(K, ' ; ',
K[optimal] == .(K.opt))),
y = 'Validation error') +
scale_x_continuous(breaks = neighbours)## Warning in geom_point(aes(x = K.opt, y = 1 - accuracy.opt.cv), colour = "red", : All aesthetics have length 1, but the data has 24 rows.
## ℹ Please consider using `annotate()` or provide this layer with data containing
## a single row.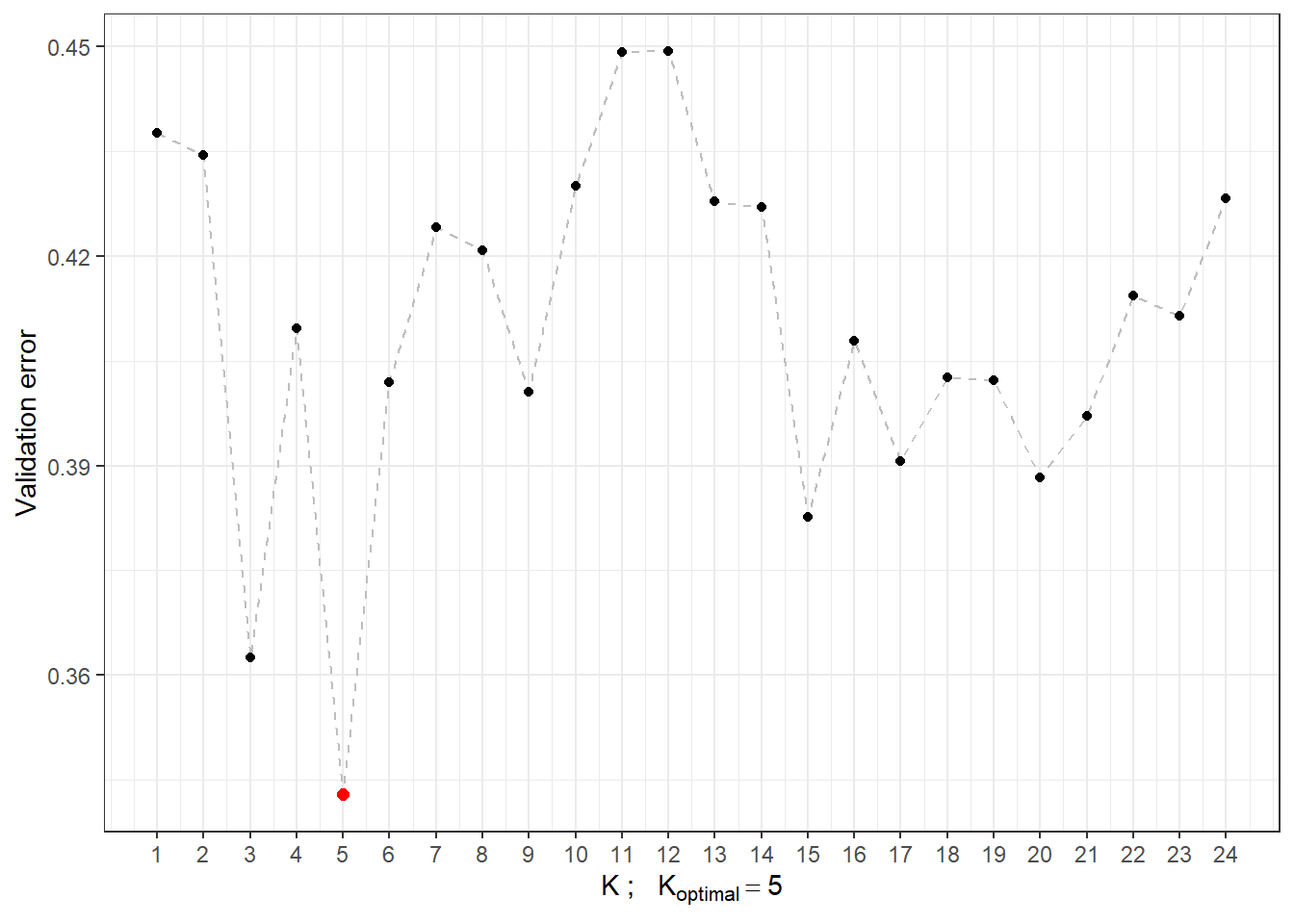
Figure 2.3: Dependence of validation error on the value of \(K\), i.e., the number of neighbors.
Now that we know the optimal value of the parameter \(K\), we can assemble the final model.
Code
neighb.model <- classif.knn(group = y.train, fdataobj = x.train, knn = K.opt)
# predictions
model.neighb.predict <- predict(neighb.model,
new.fdataobj = fdata(X.test))
# summary(neighb.model)
# accuracy on the test data
accuracy <- table(as.numeric(factor(Y.test)), model.neighb.predict) |>
prop.table() |>
diag() |>
sum()
# error rate
# 1 - accuracyThus, we can see that the error rate of the model constructed using the \(K\) nearest neighbors method with the optimal choice of \(K_{optimal}\) equal to 5, which we determined through cross-validation, is 0.3571 on the training data and 0.3833 on the test data.
To compare individual models, we can use both types of error rates; for clarity, we will store them in a table.
2.3.2 Linear Discriminant Analysis
As a second method for constructing a classifier, we will consider Linear Discriminant Analysis (LDA). Since this method cannot be applied to functional data, we must first discretize it, which we will do using Functional Principal Component Analysis. We will then perform the classification algorithm on the scores of the first \(p\) principal components. We will choose the number of components \(p\) such that the first \(p\) principal components together explain at least 90% of the variability in the data.
So let’s first perform Functional Principal Component Analysis and determine the number \(p\).
Code
# principal component analysis
data.PCA <- pca.fd(X.train, nharm = 10) # nharm - maximum number of principal components
nharm <- which(cumsum(data.PCA$varprop) >= 0.9)[1] # determine p
if(nharm == 1) nharm <- 2
data.PCA <- pca.fd(X.train, nharm = nharm)
data.PCA.train <- as.data.frame(data.PCA$scores) # scores of the first p principal components
data.PCA.train$Y <- factor(Y.train) # class membershipIn this particular case, we have taken the number of principal components to be $p = 2, which together explain 98.72% of the variability in the data. The first principal component explains 98.2% and the second 0.52% of the variability. We can graphically display the scores of the first two principal components, color-coded according to class membership.
Code
data.PCA.train |> ggplot(aes(x = V1, y = V2, colour = Y)) +
geom_point(size = 1.5) +
labs(x = paste('1st principal component (explained variance',
round(100 * data.PCA$varprop[1], 2), '%)'),
y = paste('2nd principal component (',
round(100 * data.PCA$varprop[2], 2), '%)'),
colour = 'Group') +
scale_colour_discrete(labels = c('Y = 0', 'Y = 1')) +
theme_bw()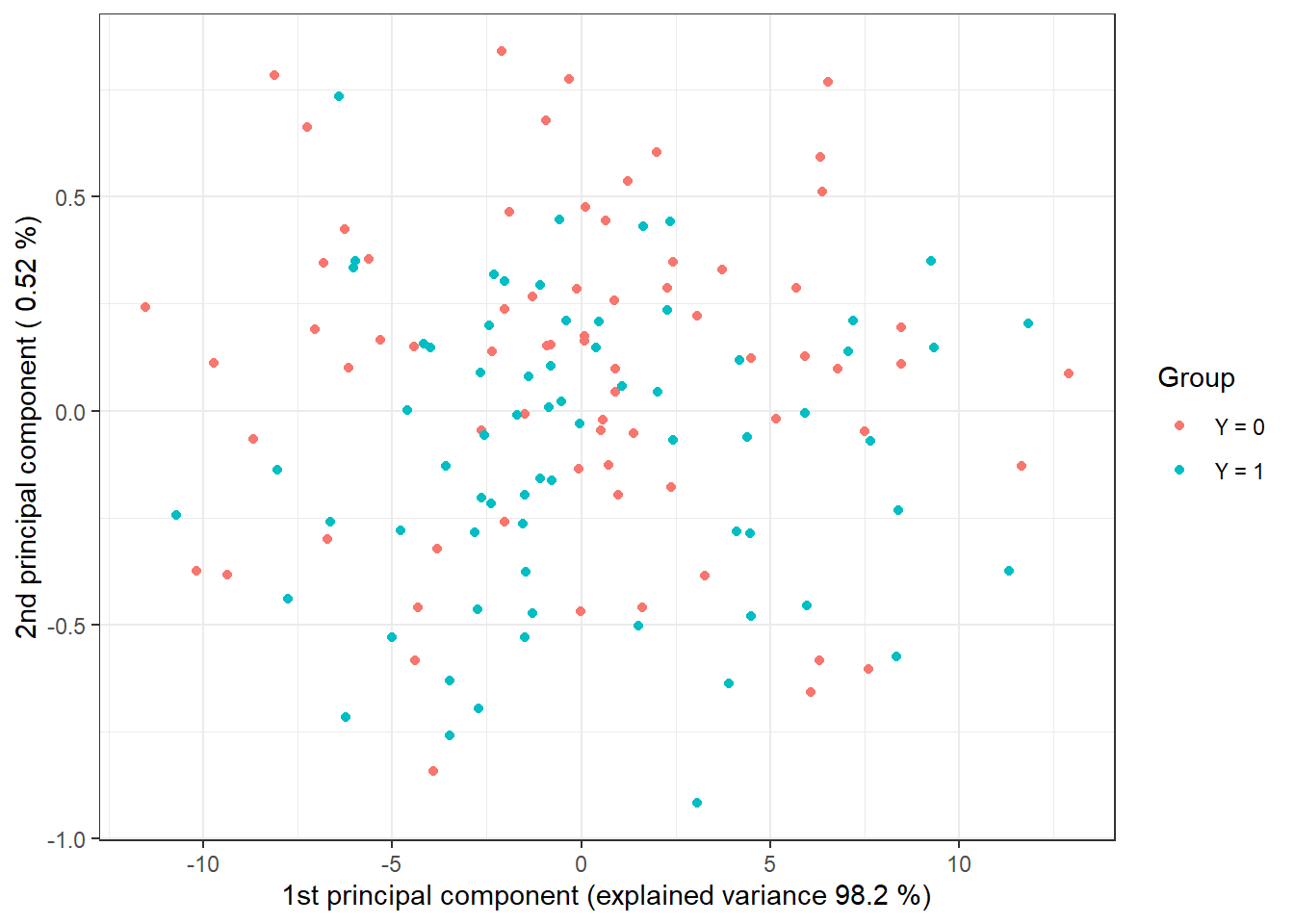
Figure 2.4: Scores of the first two principal components for the training data. Points are color-coded according to class membership.
To determine the classification accuracy on the test data, we need to calculate the scores for the first 2 principal components for the test data. These scores can be determined using the formula:
\[ \xi_{i, j} = \int \left( X_i(t) - \mu(t)\right) \cdot \rho_j(t)\text{ dt}, \]
where \(\mu(t)\) is the mean function and \(\rho_j(t)\) is the eigenfunction (functional principal component).
Code
# calculate scores for test functions
scores <- matrix(NA, ncol = nharm, nrow = length(Y.test)) # empty matrix
for(k in 1:dim(scores)[1]) {
xfd = X.test[k] - data.PCA$meanfd[1] # k-th observation - mean function
scores[k, ] = inprod(xfd, data.PCA$harmonics)
# scalar product of the residual and the eigenfunctions rho (functional principal components)
}
data.PCA.test <- as.data.frame(scores)
data.PCA.test$Y <- factor(Y.test)
colnames(data.PCA.test) <- colnames(data.PCA.train) Now we can construct the classifier on the training part of the data.
Code
# model
clf.LDA <- lda(Y ~ ., data = data.PCA.train)
# accuracy on the training data
predictions.train <- predict(clf.LDA, newdata = data.PCA.train)
accuracy.train <- table(data.PCA.train$Y, predictions.train$class) |>
prop.table() |> diag() |> sum()
# accuracy on the test data
predictions.test <- predict(clf.LDA, newdata = data.PCA.test)
accuracy.test <- table(data.PCA.test$Y, predictions.test$class) |>
prop.table() |> diag() |> sum()We have calculated the error rate of the classifier on the training (41.43%) and test data (40%).
To graphically illustrate the method, we can mark the decision boundary in the score plot of the first two principal components. This boundary will be calculated on a dense grid of points and displayed using the geom_contour() function.
Code
# add decision boundary
np <- 1001 # number of grid points
# x-axis ... 1st PC
nd.x <- seq(from = min(data.PCA.train$V1),
to = max(data.PCA.train$V1), length.out = np)
# y-axis ... 2nd PC
nd.y <- seq(from = min(data.PCA.train$V2),
to = max(data.PCA.train$V2), length.out = np)
# case for 2 PCs ... p = 2
nd <- expand.grid(V1 = nd.x, V2 = nd.y)
# case for p = 3
if(dim(data.PCA.train)[2] == 4) {
nd <- expand.grid(V1 = nd.x, V2 = nd.y, V3 = data.PCA.train$V3[1])}
# case for p = 4
if(dim(data.PCA.train)[2] == 5) {
nd <- expand.grid(V1 = nd.x, V2 = nd.y, V3 = data.PCA.train$V3[1],
V4 = data.PCA.train$V4[1])}
# case for p = 5
if(dim(data.PCA.train)[2] == 6) {
nd <- expand.grid(V1 = nd.x, V2 = nd.y, V3 = data.PCA.train$V3[1],
V4 = data.PCA.train$V4[1], V5 = data.PCA.train$V5[1])}
# add Y = 0, 1
nd <- nd |> mutate(prd = as.numeric(predict(clf.LDA, newdata = nd)$class))
data.PCA.train |> ggplot(aes(x = V1, y = V2, colour = Y)) +
geom_point(size = 1.5) +
labs(x = paste('1st principal component (explained variance',
round(100 * data.PCA$varprop[1], 2), '%)'),
y = paste('2nd principal component (',
round(100 * data.PCA$varprop[2], 2), '%)'),
colour = 'Group') +
scale_colour_discrete(labels = c('Y = 0', 'Y = 1')) +
theme_bw() +
geom_contour(data = nd, aes(x = V1, y = V2, z = prd), colour = 'black')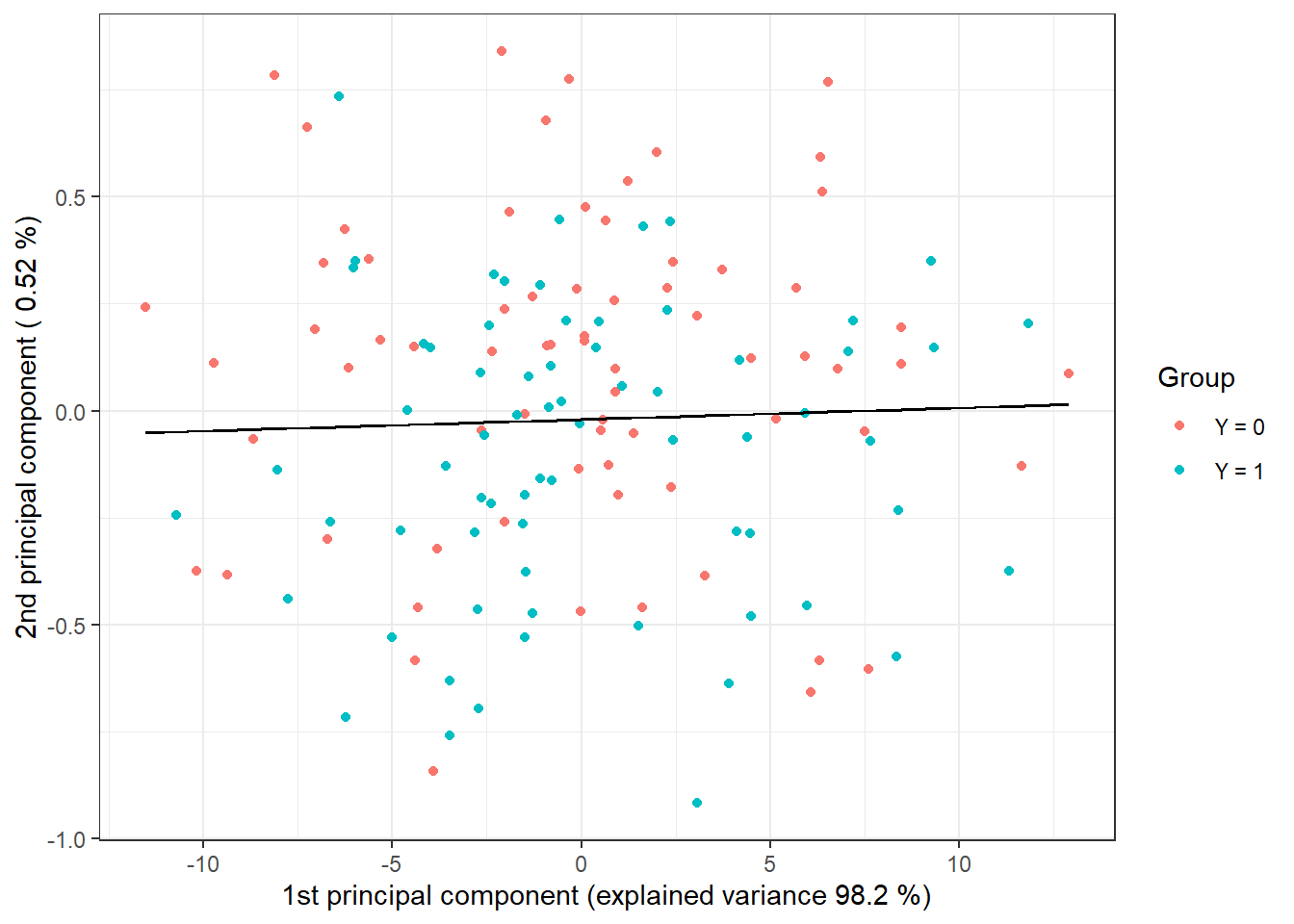
Figure 2.5: Scores of the first two principal components, color-coded by class membership. The decision boundary (line in the plane of the first two principal components) between classes constructed using LDA is indicated in black.
We can see that the decision boundary is a line, a linear function in the 2D space, which we expected from LDA. Finally, we will add the error rates to the summary table.
2.3.3 Quadratic Discriminant Analysis
Next, we will construct a classifier using Quadratic Discriminant Analysis (QDA). This is an analogous case to LDA, with the difference that we now allow for different covariance matrices for each class of the normal distribution from which the corresponding scores are derived. This relaxed assumption of equal covariance matrices leads to a quadratic boundary between classes.
In R, QDA can be performed similarly to LDA in the previous section. Therefore, we will calculate the scores for both training and test functions using Functional Principal Component Analysis, construct the classifier on the scores of the first \(p\) principal components, and use it to predict the class membership of the test curves to class \(Y^* \in \{0, 1\}\).
We do not need to perform functional PCA again, as we will utilize the results from the LDA section.
We can proceed directly to constructing the classifier using the qda() function. Next, we will calculate the accuracy of the classifier on the test and training data.
Code
# model
clf.QDA <- qda(Y ~ ., data = data.PCA.train)
# accuracy on training data
predictions.train <- predict(clf.QDA, newdata = data.PCA.train)
accuracy.train <- table(data.PCA.train$Y, predictions.train$class) |>
prop.table() |> diag() |> sum()
# accuracy on test data
predictions.test <- predict(clf.QDA, newdata = data.PCA.test)
accuracy.test <- table(data.PCA.test$Y, predictions.test$class) |>
prop.table() |> diag() |> sum()Thus, we have calculated the error rate of the classifier on the training (35.71 %) and the test data (40 %).
For a graphical representation of the method, we can mark the decision boundary in the score plot of the first two principal components. We will calculate this boundary on a dense grid of points and display it using the geom_contour() function, just as in the case of LDA.
Code
nd <- nd |> mutate(prd = as.numeric(predict(clf.QDA, newdata = nd)$class))
data.PCA.train |> ggplot(aes(x = V1, y = V2, colour = Y)) +
geom_point(size = 1.5) +
labs(x = paste('1st principal component (explained variance',
round(100 * data.PCA$varprop[1], 2), '%)'),
y = paste('2nd principal component (',
round(100 * data.PCA$varprop[2], 2), '%)'),
colour = 'Group') +
scale_colour_discrete(labels = c('Y = 0', 'Y = 1')) +
theme_bw() +
geom_contour(data = nd, aes(x = V1, y = V2, z = prd), colour = 'black')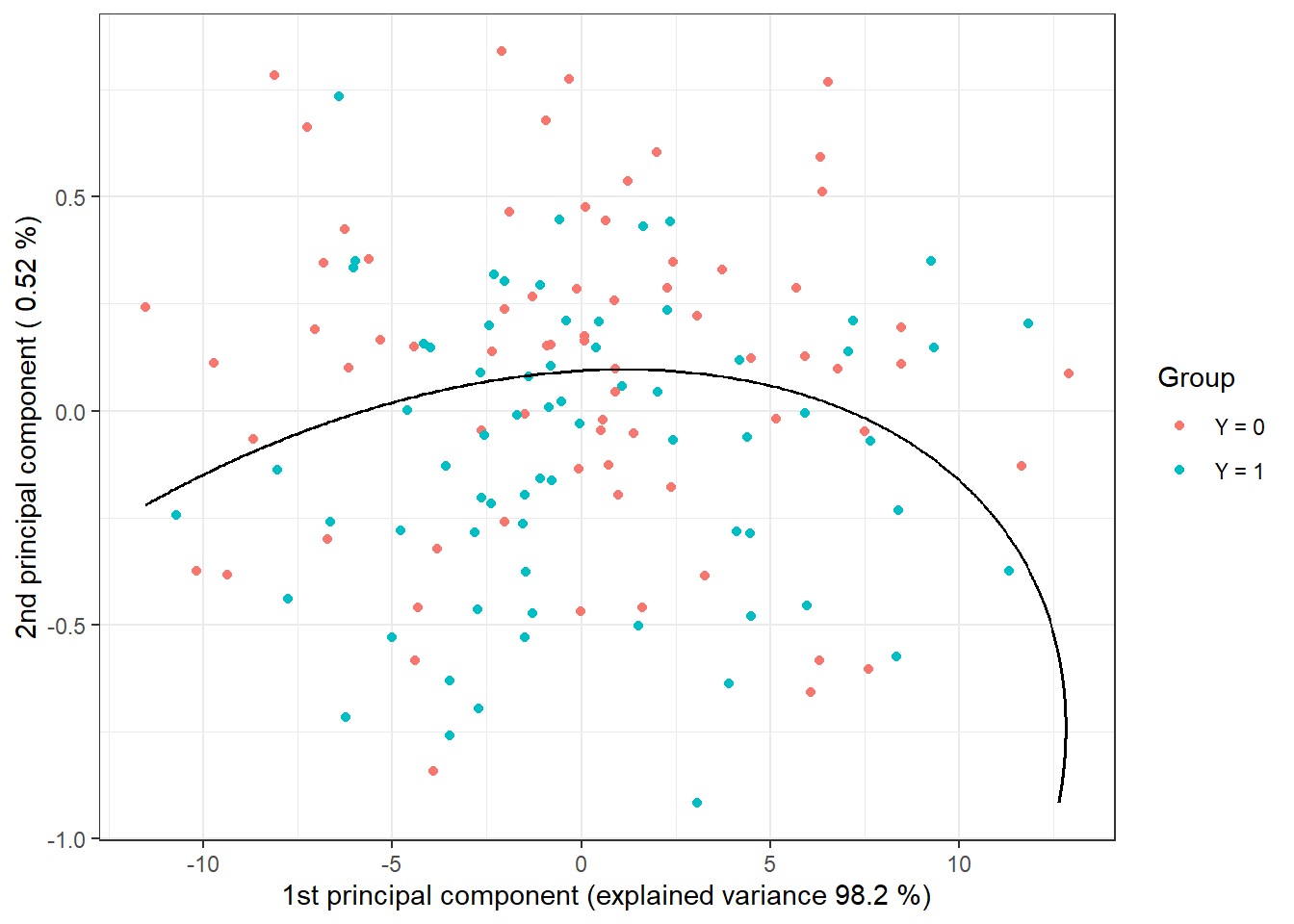
Figure 2.6: Scores of the first two principal components, color-coded by classification group. The decision boundary (a parabola in the plane of the first two principal components) between classes constructed using QDA is marked in black.
Note that the decision boundary between the classification classes is now a parabola.
Finally, we will add the error rates to the summary table.
2.3.4 Logistic Regression
Logistic regression can be performed in two ways. One can either use the functional analogue of classic logistic regression or the classic multivariate logistic regression, which we will perform on the scores of the first \(p\) principal components.
2.3.4.1 Functional Logistic Regression
Analogous to the case of finite dimension input data, we consider the logistic model in the form:
\[ g\left(\mathbb E [Y|X = x]\right) = \eta (x) = g(\pi(x)) = \alpha + \int \beta(t)\cdot x(t) \text d t, \] where \(\eta(x)\) is the linear predictor taking values from the interval \((-\infty, \infty)\), \(g(\cdot)\) is the link function, and in the case of logistic regression, it is the logit function \(g: (0,1) \rightarrow \mathbb R,\ g(p) = \ln\frac{p}{1-p}\), and \(\pi(x)\) is the conditional probability
\[ \pi(x) = \text{Pr}(Y = 1 | X = x) = g^{-1}(\eta(x)) = \frac{\text e^{\alpha + \int \beta(t)\cdot x(t) \text d t}}{1 + \text e^{\alpha + \int \beta(t)\cdot x(t) \text d t}}, \]
where \(\alpha\) is a constant and \(\beta(t) \in L^2[a, b]\) is a parametric function. Our goal is to estimate this parametric function.
For functional logistic regression, we will use the fregre.glm() function from the fda.usc package. First, we will create suitable objects for constructing the classifier.
Code
To estimate the parametric function \(\beta(t)\), we need to express it in some basis representation, in our case, B-spline basis. However, we need to find a suitable number of basis functions. We could determine this based on the error rate on the training data; however, this data will favor selecting a large number of bases, leading to model overfitting.
Let’s illustrate this with the following case. For each number of bases \(n_{basis} \in \{4, 5, \dots, 50\}\), we will train a model on the training data, determine the error rate on this data, and also calculate the error rate on the test data. Remember that we cannot use the same data for estimating the test error rate, as it would underestimate this error.
Code
n.basis.max <- 50
n.basis <- 4:n.basis.max
pred.baz <- matrix(NA, nrow = length(n.basis), ncol = 2,
dimnames = list(n.basis, c('Err.train', 'Err.test')))
for (i in n.basis) {
# bases for betas
basis2 <- create.bspline.basis(rangeval = range(tt), nbasis = i)
# relationship
f <- Y ~ x
# bases for x and betas
basis.x <- list("x" = basis1) # smoothed data
basis.b <- list("x" = basis2)
# input data for the model
ldata <- list("df" = dataf, "x" = x.train)
# binomial model ... logistic regression model
model.glm <- fregre.glm(f, family = binomial(), data = ldata,
basis.x = basis.x, basis.b = basis.b)
# accuracy on training data
predictions.train <- predict(model.glm, newx = ldata)
predictions.train <- data.frame(Y.pred = ifelse(predictions.train < 1/2, 0, 1))
presnost.train <- table(Y.train, predictions.train$Y.pred) |>
prop.table() |> diag() |> sum()
# accuracy on test data
newldata = list("df" = as.data.frame(Y.test), "x" = fdata(X.test))
predictions.test <- predict(model.glm, newx = newldata)
predictions.test <- data.frame(Y.pred = ifelse(predictions.test < 1/2, 0, 1))
presnost.test <- table(Y.test, predictions.test$Y.pred) |>
prop.table() |> diag() |> sum()
# insert into matrix
pred.baz[as.character(i), ] <- 1 - c(presnost.train, presnost.test)
}
pred.baz <- as.data.frame(pred.baz)
pred.baz$n.basis <- n.basisLet’s visualize the progression of both types of error in a graph depending on the number of basis functions.
Code
n.basis.beta.opt <- pred.baz$n.basis[which.min(pred.baz$Err.test)]
pred.baz |> ggplot(aes(x = n.basis, y = Err.test)) +
geom_line(linetype = 'dashed', colour = 'black') +
geom_line(aes(x = n.basis, y = Err.train), colour = 'deepskyblue3',
linetype = 'dashed', linewidth = 0.5) +
geom_point(size = 1.5) +
geom_point(aes(x = n.basis, y = Err.train), colour = 'deepskyblue3',
size = 1.5) +
geom_point(aes(x = n.basis.beta.opt, y = min(pred.baz$Err.test)),
colour = 'red', size = 2) +
theme_bw() +
labs(x = bquote(paste(n[basis], ' ; ',
n[optimal] == .(n.basis.beta.opt))),
y = 'Error Rate')## Warning: Use of `pred.baz$Err.test` is discouraged.
## ℹ Use `Err.test` instead.## Warning in geom_point(aes(x = n.basis.beta.opt, y = min(pred.baz$Err.test)), : All aesthetics have length 1, but the data has 47 rows.
## ℹ Please consider using `annotate()` or provide this layer with data containing
## a single row.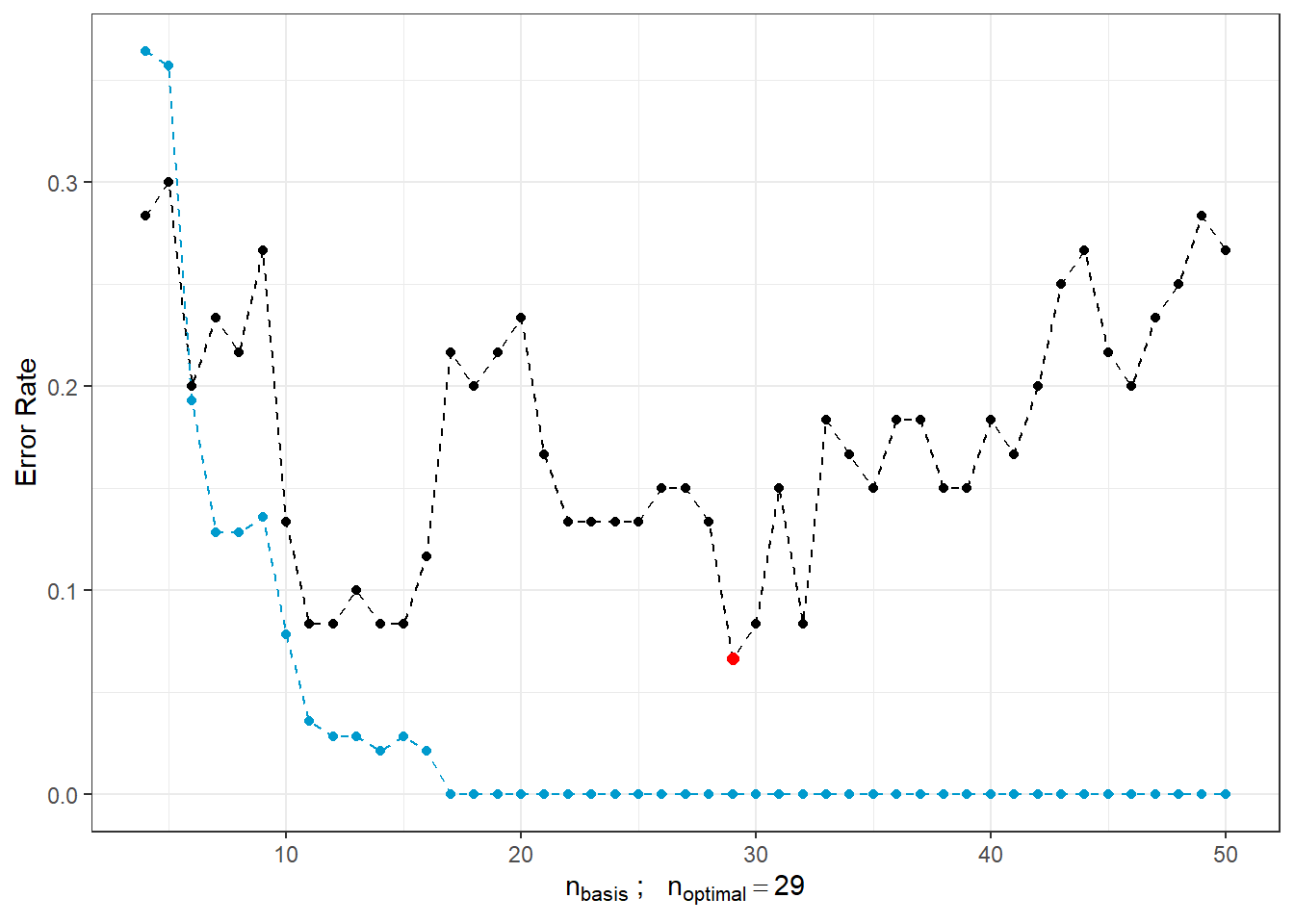
Figure 2.7: Dependence of test and training error rates on the number of basis functions for \(\beta\). The red point indicates the optimal number \(n_{optimal}\) chosen as the minimum test error rate, the black line depicts the test error, and the blue dashed line shows the progression of training error rate.
We see that as the number of bases for \(\beta(t)\) increases, the training error rate (blue line) tends to decrease, leading us to select large values of \(n_{basis}\) based on it. Conversely, the optimal choice based on the test error rate is \(n\) equal to 29, which is significantly smaller than 50. Meanwhile, as \(n\) increases, the test error increases, indicating model overfitting.
For the above reasons, to determine the optimal number of basis functions for \(\beta(t)\), we will utilize 10-fold cross-validation. We will consider a maximum number of basis functions of 25, as we observed that above this value, overfitting occurs.
Code
### 10-fold cross-validation
n.basis.max <- 25
n.basis <- 4:n.basis.max
k_cv <- 10 # k-fold CV
# split the training data into k parts
folds <- createMultiFolds(X.train$fdnames$reps, k = k_cv, time = 1)
## elements that do not change during the loop
# points at which the functions are evaluated
tt <- x.train[["argvals"]]
rangeval <- range(tt)
# B-spline bases
basis1 <- X.train$basis
# relationship
f <- Y ~ x
# bases for x
basis.x <- list("x" = basis1)
# empty matrix to store individual results
# in columns, there will be accuracy values for each part of the training set
# in rows, there will be values for the given number of bases
CV.results <- matrix(NA, nrow = length(n.basis), ncol = k_cv,
dimnames = list(n.basis, 1:k_cv))Now we have everything prepared to calculate the error on each of the ten subsets of the training set.
Next, we will determine the average and take the argument of the minimum validation error as the optimal \(n\).
Code
for (index in 1:k_cv) {
# define the specific index set
fold <- folds[[index]]
x.train.cv <- subset(X.train, c(1:length(X.train$fdnames$reps)) %in% fold) |>
fdata()
y.train.cv <- subset(Y.train, c(1:length(X.train$fdnames$reps)) %in% fold) |>
as.numeric()
x.test.cv <- subset(X.train, !c(1:length(X.train$fdnames$reps)) %in% fold) |>
fdata()
y.test.cv <- subset(Y.train, !c(1:length(X.train$fdnames$reps)) %in% fold) |>
as.numeric()
dataf <- as.data.frame(y.train.cv)
colnames(dataf) <- "Y"
for (i in n.basis) {
# bases for betas
basis2 <- create.bspline.basis(rangeval = rangeval, nbasis = i)
basis.b <- list("x" = basis2)
# input data for the model
ldata <- list("df" = dataf, "x" = x.train.cv)
# binomial model ... logistic regression model
model.glm <- fregre.glm(f, family = binomial(), data = ldata,
basis.x = basis.x, basis.b = basis.b)
# accuracy on validation part
newldata = list("df" = as.data.frame(y.test.cv), "x" = x.test.cv)
predictions.valid <- predict(model.glm, newx = newldata)
predictions.valid <- data.frame(Y.pred = ifelse(predictions.valid < 1/2, 0, 1))
presnost.valid <- table(y.test.cv, predictions.valid$Y.pred) |>
prop.table() |> diag() |> sum()
# insert into the matrix
CV.results[as.character(i), as.character(index)] <- presnost.valid
}
}
# calculate average accuracy for each n over folds
CV.results <- apply(CV.results, 1, mean)
n.basis.opt <- n.basis[which.max(CV.results)]
presnost.opt.cv <- max(CV.results)
# CV.resultsLet’s also plot the validation error course with the optimal value of \(n_{optimal}\) equal to 11 and validation error 0.072 highlighted.
Code
CV.results <- data.frame(n.basis = n.basis, CV = CV.results)
CV.results |> ggplot(aes(x = n.basis, y = 1 - CV)) +
geom_line(linetype = 'dashed', colour = 'grey') +
geom_point(size = 1.5) +
geom_point(aes(x = n.basis.opt, y = 1 - presnost.opt.cv), colour = 'red', size = 2) +
theme_bw() +
labs(x = bquote(paste(n[basis], ' ; ',
n[optimal] == .(n.basis.opt))),
y = 'Validation error') +
scale_x_continuous(breaks = n.basis)## Warning in geom_point(aes(x = n.basis.opt, y = 1 - presnost.opt.cv), colour = "red", : All aesthetics have length 1, but the data has 22 rows.
## ℹ Please consider using `annotate()` or provide this layer with data containing
## a single row.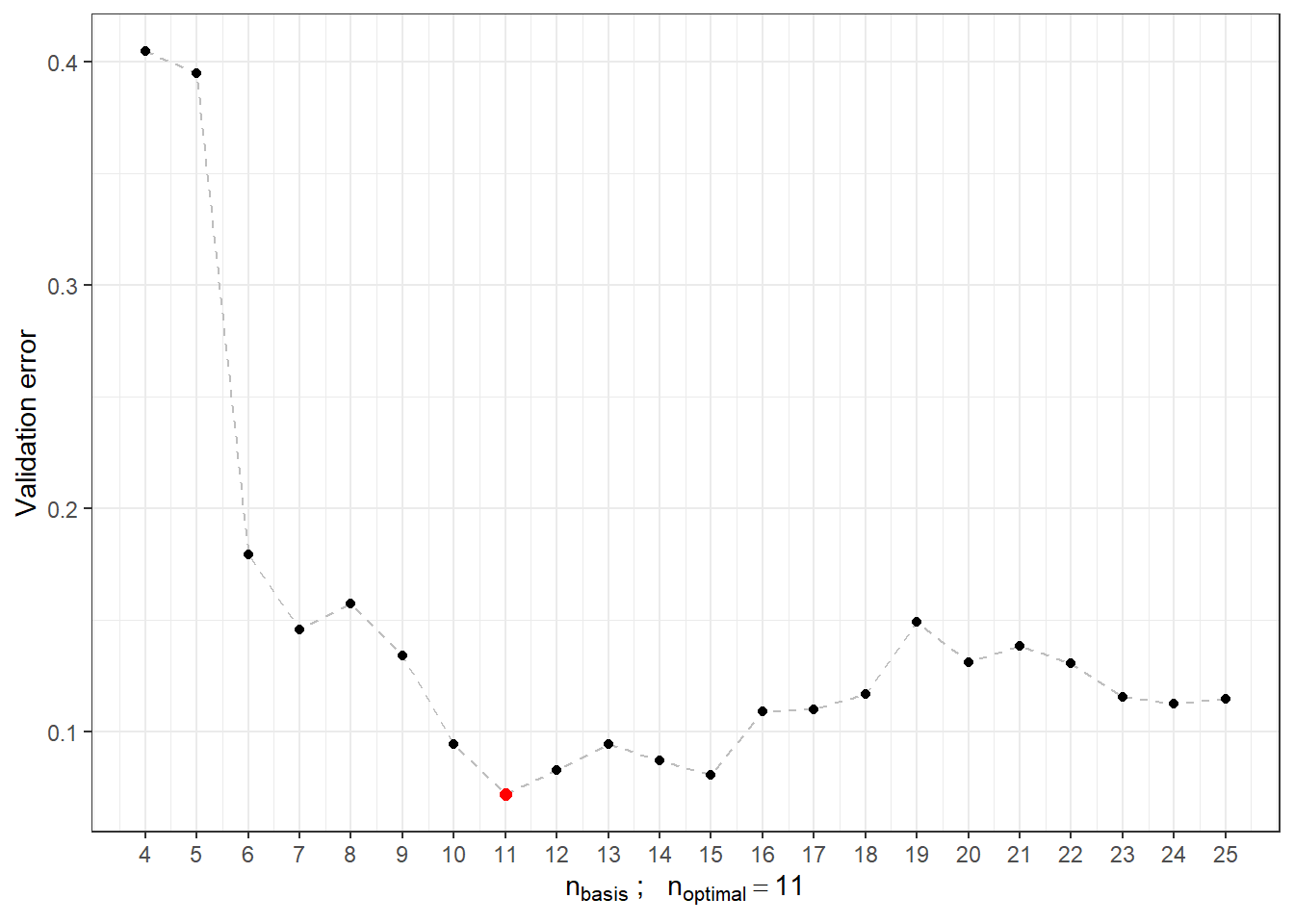
Figure 2.8: Dependency of validation error on the value of \(n_{basis}\), i.e., on the number of bases.
We can now define the final model using functional logistic regression, choosing the B-spline basis for \(\beta(t)\) with 11 bases.
Code
# optimal model
basis2 <- create.bspline.basis(rangeval = range(tt), nbasis = n.basis.opt)
f <- Y ~ x
# bases for x and betas
basis.x <- list("x" = basis1)
basis.b <- list("x" = basis2)
# input data for the model
dataf <- as.data.frame(y.train)
colnames(dataf) <- "Y"
ldata <- list("df" = dataf, "x" = x.train)
# binomial model ... logistic regression model
model.glm <- fregre.glm(f, family = binomial(), data = ldata,
basis.x = basis.x, basis.b = basis.b)
# accuracy on training data
predictions.train <- predict(model.glm, newx = ldata)
predictions.train <- data.frame(Y.pred = ifelse(predictions.train < 1/2, 0, 1))
presnost.train <- table(Y.train, predictions.train$Y.pred) |>
prop.table() |> diag() |> sum()
# accuracy on test data
newldata = list("df" = as.data.frame(Y.test), "x" = fdata(X.test))
predictions.test <- predict(model.glm, newx = newldata)
predictions.test <- data.frame(Y.pred = ifelse(predictions.test < 1/2, 0, 1))
presnost.test <- table(Y.test, predictions.test$Y.pred) |>
prop.table() |> diag() |> sum()We calculated the training error rate (which is 3.57 %) and the test error rate (which is 8.33 %). To get a better understanding, we can also plot the estimated probabilities of belonging to the classification class \(Y = 1\) based on the values of the linear predictor in the training data.
Code
data.frame(
linear.predictor = model.glm$linear.predictors,
response = model.glm$fitted.values,
Y = factor(y.train)
) |> ggplot(aes(x = linear.predictor, y = response, colour = Y)) +
geom_point(size = 1.5) +
scale_colour_discrete(labels = c('Y = 0', 'Y = 1')) +
geom_abline(aes(slope = 0, intercept = 0.5), linetype = 'dashed') +
theme_bw() +
labs(x = 'Linear predictor',
y = 'Estimated probabilities Pr(Y = 1|X = x)',
colour = 'Class') 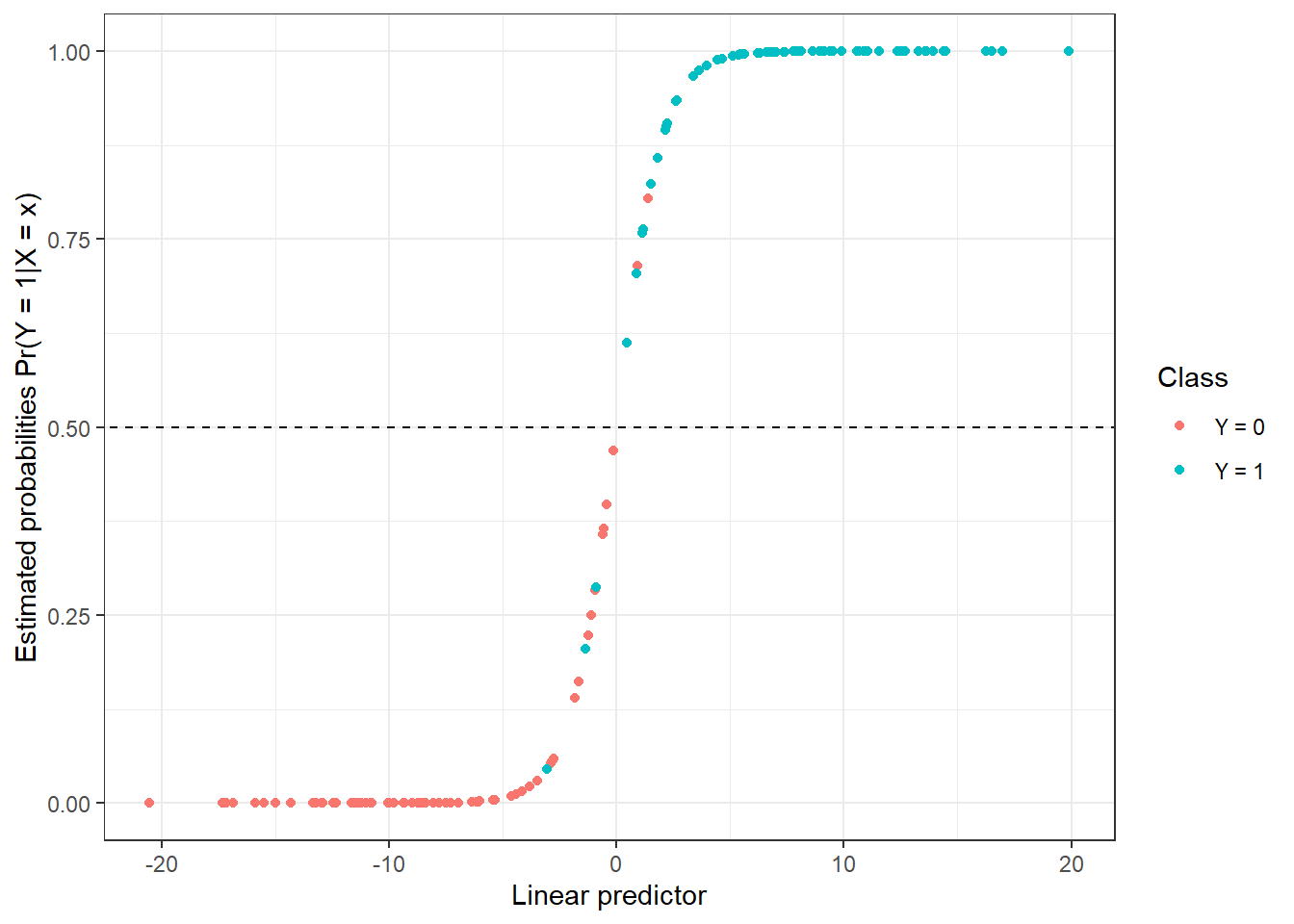
Figure 1.15: Dependence of estimated probabilities on the values of the linear predictor. Points are color-coded according to class membership.
We can also visualize the estimated parametric function \(\beta(t)\).
Code
t.seq <- seq(0, 6, length = 1001)
beta.seq <- eval.fd(evalarg = t.seq, fdobj = model.glm$beta.l$x)
data.frame(t = t.seq, beta = beta.seq) |>
ggplot(aes(t, beta)) +
geom_line() +
theme_bw() +
labs(x = 'Time',
y = expression(widehat(beta)(t))) +
theme(panel.grid.major = element_blank(), panel.grid.minor = element_blank()) +
geom_abline(aes(slope = 0, intercept = 0), linetype = 'dashed',
linewidth = 0.5, colour = 'grey')![Plot of the estimate of the parametric function $\beta(t), t \in [0, 6]$.](02-Simulace_sigma_files/figure-html/unnamed-chunk-47-1.png)
Figure 2.9: Plot of the estimate of the parametric function \(\beta(t), t \in [0, 6]\).
We will again add the results to the summary table.
2.3.5 Random Forests
The classifier built using the random forest method consists of constructing several individual decision trees, which are then combined to create a common classifier (by a common “vote”).
Just like with decision trees, we have several options for what data (finite-dimensional) we will use to construct the model. We will again consider the three approaches discussed above. The data files with the respective quantities for all three approaches are already prepared from the previous section, so we can directly build the models, calculate the characteristics of the classifier, and add the results to the summary table.
2.3.5.1 Discretization of the Interval
In the first case, we evaluate the functions at a given grid of points in the interval \(I = [0, 6]\).
Code
grid.data <- eval.fd(fdobj = X.train, evalarg = t.seq)
grid.data <- as.data.frame(t(grid.data)) # transpose for row-wise functions
grid.data$Y <- Y.train |> factor()
grid.data.test <- eval.fd(fdobj = X.test, evalarg = t.seq)
grid.data.test <- as.data.frame(t(grid.data.test))
grid.data.test$Y <- Y.test |> factor()Code
# model construction
clf.RF <- randomForest(Y ~ ., data = grid.data,
ntree = 500, # number of trees
importance = TRUE,
nodesize = 5)
# accuracy on training data
predictions.train <- predict(clf.RF, newdata = grid.data)
presnost.train <- table(Y.train, predictions.train) |>
prop.table() |> diag() |> sum()
# accuracy on test data
predictions.test <- predict(clf.RF, newdata = grid.data.test)
presnost.test <- table(Y.test, predictions.test) |>
prop.table() |> diag() |> sum()The error rate of the random forest on the training data is 0 % and on the test data is 38.33 %.
2.3.5.2 Principal Component Scores
In this case, we will use the scores of the first \(p =\) 2 principal components.
Code
# model construction
clf.RF.PCA <- randomForest(Y ~ ., data = data.PCA.train,
ntree = 500, # number of trees
importance = TRUE,
nodesize = 5)
# accuracy on training data
predictions.train <- predict(clf.RF.PCA, newdata = data.PCA.train)
presnost.train <- table(Y.train, predictions.train) |>
prop.table() |> diag() |> sum()
# accuracy on test data
predictions.test <- predict(clf.RF.PCA, newdata = data.PCA.test)
presnost.test <- table(Y.test, predictions.test) |>
prop.table() |> diag() |> sum()The error rate on the training data is thus 3.57 %, and on the test data, it is 41.67 %.
2.3.5.3 B-Spline Coefficients
Finally, we will use the representation of functions through B-spline basis. First, let’s define the necessary data files with coefficients.
Code
Code
# model construction
clf.RF.Bbasis <- randomForest(Y ~ ., data = data.Bbasis.train,
ntree = 500, # number of trees
importance = TRUE,
nodesize = 5)
# accuracy on training data
predictions.train <- predict(clf.RF.Bbasis, newdata = data.Bbasis.train)
presnost.train <- table(Y.train, predictions.train) |>
prop.table() |> diag() |> sum()
# accuracy on test data
predictions.test <- predict(clf.RF.Bbasis, newdata = data.Bbasis.test)
presnost.test <- table(Y.test, predictions.test) |>
prop.table() |> diag() |> sum()The error rate of this classifier on the training data is 0 %, and on the test data, it is 41.67 %.
2.3.6 Support Vector Machines
Let’s define the data for the next methods.
Code
# sequence of points where we evaluate the function
t.seq <- seq(0, 6, length = 101)
grid.data <- eval.fd(fdobj = X.train, evalarg = t.seq)
grid.data <- as.data.frame(t(grid.data)) # transpose for row functions
grid.data$Y <- Y.train |> factor()
grid.data.test <- eval.fd(fdobj = X.test, evalarg = t.seq)
grid.data.test <- as.data.frame(t(grid.data.test))
grid.data.test$Y <- Y.test |> factor()First, let’s define the necessary data files with coefficients.
Code
Now, let’s look at the classification of our simulated curves using Support Vector Machines (SVM). The advantage of this classification method is its computational efficiency, as it uses only a few (often very few) observations to define the boundary curve between classes.
2.3.6.1 Interval Discretization
Let’s start by applying the Support Vector Machines method directly to the discretized data (evaluating the function on a grid of points on the interval \(I = [0, 6]\)), considering all three previously mentioned kernel functions.
Code
# set norm equal to one
norms <- c()
for (i in 1:dim(XXfd$coefs)[2]) {
norms <- c(norms, as.numeric(1 / norm.fd(XXfd[i])))
}
XXfd_norm <- XXfd
XXfd_norm$coefs <- XXfd_norm$coefs * matrix(norms,
ncol = dim(XXfd$coefs)[2],
nrow = dim(XXfd$coefs)[1],
byrow = TRUE)
# split into test and training parts
X.train_norm <- subset(XXfd_norm, split == TRUE)
X.test_norm <- subset(XXfd_norm, split == FALSE)
Y.train_norm <- subset(Y, split == TRUE)
Y.test_norm <- subset(Y, split == FALSE)
grid.data <- eval.fd(fdobj = X.train_norm, evalarg = t.seq)
grid.data <- as.data.frame(t(grid.data))
grid.data$Y <- Y.train_norm |> factor()
grid.data.test <- eval.fd(fdobj = X.test_norm, evalarg = t.seq)
grid.data.test <- as.data.frame(t(grid.data.test))
grid.data.test$Y <- Y.test_norm |> factor()We estimated the parameters for each kernel using cross-validation on one generated dataset. We will use these values of \(C\), \(d\), and \(\gamma\) for all datasets in this simulation.
Code
# model construction
clf.SVM.l <- svm(Y ~ ., data = grid.data,
type = 'C-classification',
scale = TRUE,
cost = 100,
kernel = 'linear')
clf.SVM.p <- svm(Y ~ ., data = grid.data,
type = 'C-classification',
scale = TRUE,
coef0 = 1,
cost = 100,
kernel = 'polynomial')
clf.SVM.r <- svm(Y ~ ., data = grid.data,
type = 'C-classification',
scale = TRUE,
cost = 100000,
gamma = 0.0001,
kernel = 'radial')
# accuracy on training data
predictions.train.l <- predict(clf.SVM.l, newdata = grid.data)
presnost.train.l <- table(Y.train, predictions.train.l) |>
prop.table() |> diag() |> sum()
predictions.train.p <- predict(clf.SVM.p, newdata = grid.data)
presnost.train.p <- table(Y.train, predictions.train.p) |>
prop.table() |> diag() |> sum()
predictions.train.r <- predict(clf.SVM.r, newdata = grid.data)
presnost.train.r <- table(Y.train, predictions.train.r) |>
prop.table() |> diag() |> sum()
# accuracy on test data
predictions.test.l <- predict(clf.SVM.l, newdata = grid.data.test)
presnost.test.l <- table(Y.test, predictions.test.l) |>
prop.table() |> diag() |> sum()
predictions.test.p <- predict(clf.SVM.p, newdata = grid.data.test)
presnost.test.p <- table(Y.test, predictions.test.p) |>
prop.table() |> diag() |> sum()
predictions.test.r <- predict(clf.SVM.r, newdata = grid.data.test)
presnost.test.r <- table(Y.test, predictions.test.r) |>
prop.table() |> diag() |> sum()The error rate of the SVM method on the training data is 5.71 % for the linear kernel, 2.14 % for the polynomial kernel, and 3.57 % for the radial kernel. On the test data, the error rate of the method is 16.67 % for the linear kernel, 16.67 % for the polynomial kernel, and 13.33 % for the radial kernel.
2.3.6.2 Principal Component Scores
In this case, we will use the scores of the first \(p =\) 2 principal components.
Code
# model construction
clf.SVM.l.PCA <- svm(Y ~ ., data = data.PCA.train,
type = 'C-classification',
scale = TRUE,
cost = 0.01,
kernel = 'linear')
clf.SVM.p.PCA <- svm(Y ~ ., data = data.PCA.train,
type = 'C-classification',
scale = TRUE,
coef0 = 1,
cost = 0.6,
kernel = 'polynomial')
clf.SVM.r.PCA <- svm(Y ~ ., data = data.PCA.train,
type = 'C-classification',
scale = TRUE,
cost = 1000,
gamma = 0.01,
kernel = 'radial')
# accuracy on training data
predictions.train.l <- predict(clf.SVM.l.PCA, newdata = data.PCA.train)
presnost.train.l <- table(data.PCA.train$Y, predictions.train.l) |>
prop.table() |> diag() |> sum()
predictions.train.p <- predict(clf.SVM.p.PCA, newdata = data.PCA.train)
presnost.train.p <- table(data.PCA.train$Y, predictions.train.p) |>
prop.table() |> diag() |> sum()
predictions.train.r <- predict(clf.SVM.r.PCA, newdata = data.PCA.train)
presnost.train.r <- table(data.PCA.train$Y, predictions.train.r) |>
prop.table() |> diag() |> sum()
# accuracy on test data
predictions.test.l <- predict(clf.SVM.l.PCA, newdata = data.PCA.test)
presnost.test.l <- table(data.PCA.test$Y, predictions.test.l) |>
prop.table() |> diag() |> sum()
predictions.test.p <- predict(clf.SVM.p.PCA, newdata = data.PCA.test)
presnost.test.p <- table(data.PCA.test$Y, predictions.test.p) |>
prop.table() |> diag() |> sum()
predictions.test.r <- predict(clf.SVM.r.PCA, newdata = data.PCA.test)
presnost.test.r <- table(data.PCA.test$Y, predictions.test.r) |>
prop.table() |> diag() |> sum()The error rate of the SVM method applied to the principal component scores on the training data is 44.29 % for the linear kernel, 37.86 % for the polynomial kernel, and 37.14 % for the radial kernel. On the test data, the error rate of the method is 48.33 % for the linear kernel, 43.33 % for the polynomial kernel, and 40 % for the radial kernel.
For the graphical representation of the method, we can mark the decision boundary on the plot of the scores of the first two principal components. We will calculate this boundary on a dense grid of points and display it using the geom_contour() function, as we did in previous cases when plotting the classification boundary.
Code
nd <- rbind(nd, nd, nd) |> mutate(
prd = c(as.numeric(predict(clf.SVM.l.PCA, newdata = nd, type = 'response')),
as.numeric(predict(clf.SVM.p.PCA, newdata = nd, type = 'response')),
as.numeric(predict(clf.SVM.r.PCA, newdata = nd, type = 'response'))),
kernel = rep(c('linear', 'polynomial', 'radial'),
each = length(as.numeric(predict(clf.SVM.l.PCA,
newdata = nd,
type = 'response')))))
data.PCA.train |> ggplot(aes(x = V1, y = V2, colour = Y)) +
geom_point(size = 1.5) +
labs(x = paste('1st Principal Component (Explained Variability',
round(100 * data.PCA$varprop[1], 2), '%)'),
y = paste('2nd Principal Component (',
round(100 * data.PCA$varprop[2], 2), '%)'),
colour = 'Group',
linetype = 'Kernel type') +
scale_colour_discrete(labels = c('Y = 0', 'Y = 1')) +
theme_bw() +
geom_contour(data = nd, aes(x = V1, y = V2, z = prd, linetype = kernel),
colour = 'black') +
geom_contour(data = nd, aes(x = V1, y = V2, z = prd, linetype = kernel),
colour = 'black') +
geom_contour(data = nd, aes(x = V1, y = V2, z = prd, linetype = kernel),
colour = 'black')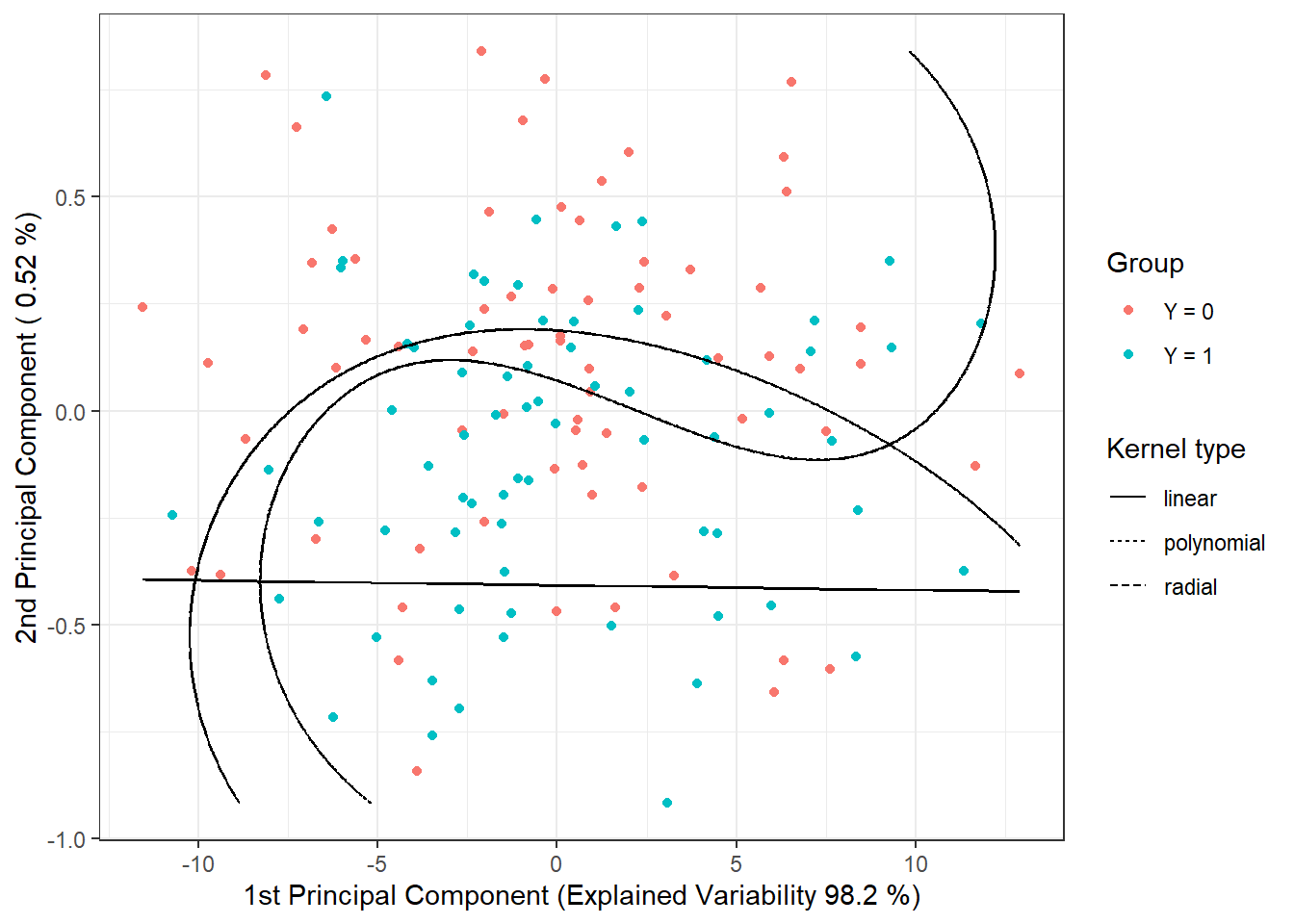
Figure 2.10: Scores of the first two principal components, color-coded according to class membership. The decision boundary (line or curves in the plane of the first two principal components) between classes constructed using the SVM method is marked in black.
2.3.6.3 B-spline Coefficients
Finally, we will use the representation of functions through the B-spline basis.
Code
# model construction
clf.SVM.l.Bbasis <- svm(Y ~ ., data = data.Bbasis.train,
type = 'C-classification',
scale = TRUE,
cost = 500,
kernel = 'linear')
clf.SVM.p.Bbasis <- svm(Y ~ ., data = data.Bbasis.train,
type = 'C-classification',
scale = TRUE,
coef0 = 1,
cost = 500,
kernel = 'polynomial')
clf.SVM.r.Bbasis <- svm(Y ~ ., data = data.Bbasis.train,
type = 'C-classification',
scale = TRUE,
cost = 1000,
gamma = 0.005,
kernel = 'radial')
# accuracy on training data
predictions.train.l <- predict(clf.SVM.l.Bbasis, newdata = data.Bbasis.train)
presnost.train.l <- table(Y.train, predictions.train.l) |>
prop.table() |> diag() |> sum()
predictions.train.p <- predict(clf.SVM.p.Bbasis, newdata = data.Bbasis.train)
presnost.train.p <- table(Y.train, predictions.train.p) |>
prop.table() |> diag() |> sum()
predictions.train.r <- predict(clf.SVM.r.Bbasis, newdata = data.Bbasis.train)
presnost.train.r <- table(Y.train, predictions.train.r) |>
prop.table() |> diag() |> sum()
# accuracy on test data
predictions.test.l <- predict(clf.SVM.l.Bbasis, newdata = data.Bbasis.test)
presnost.test.l <- table(Y.test, predictions.test.l) |>
prop.table() |> diag() |> sum()
predictions.test.p <- predict(clf.SVM.p.Bbasis, newdata = data.Bbasis.test)
presnost.test.p <- table(Y.test, predictions.test.p) |>
prop.table() |> diag() |> sum()
predictions.test.r <- predict(clf.SVM.r.Bbasis, newdata = data.Bbasis.test)
presnost.test.r <- table(Y.test, predictions.test.r) |>
prop.table() |> diag() |> sum()The error rate of the SVM method applied to the basis coefficients on the training data is therefore 4.29 % for the linear kernel, 4.29 % for the polynomial kernel, and 7.14 % for the Gaussian kernel. For the test data, the error rate of the method is 10 % for the linear kernel, 11.67 % for the polynomial kernel, and 15 % for the radial kernel.
2.3.6.4 Projection onto B-spline Basis
Another way to apply the classical SVM method to functional data is to project the original data onto a \(d\)-dimensional subspace of our Hilbert space \(\mathcal{H}\), which we denote as \(V_d\). Let’s assume that this subspace \(V_d\) has an orthonormal basis \(\{\Psi_j\}_{j = 1, \dots, d}\). We define the transformation $ P_{V_d} $ as the orthogonal projection onto the subspace $ V_d $, which can be expressed as
\[ P_{V_d} (x) = \sum_{j = 1}^d \langle x, \Psi_j \rangle \Psi_j. \]
We can then use the coefficients from the orthogonal projection for classification, applying standard SVM to the vectors $ ( x, 1 , , x, d )^$. By utilizing this transformation, we define a new, so-called adapted kernel, composed of the orthogonal projection $ P{V_d} $ and the kernel function of the standard support vector machine. Thus, we have the (adapted) kernel $ Q(x_i, x_j) = K(P{V_d}(x_i), P_{V_d}(x_j)) $. This represents a dimensionality reduction method, which we can refer to as filtering.
For the projection itself, we will use the project.basis() function from the fda library in R. The input will be a matrix of original discrete (non-smoothed) data, the values over which we measure the values in the original data matrix, and the basis object onto which we want to project the data. We will choose to project onto a B-spline basis because using a Fourier basis is not suitable for our non-periodic data. Another option is to use a wavelet basis.
The dimension $ d $ can be chosen based on some prior expert knowledge or through cross-validation. In our case, we will determine the optimal dimension of the subspace $ V_d $ using $ k $-fold cross-validation (we choose $ k n $ due to the computational intensity of the method, often selecting $ k = 5 $ or $ k = 10 $). We require B-splines of order 4, and the number of basis functions is determined by the relation
\[ n_{basis} = n_{breaks} + n_{order} - 2, \]
where $ n_{breaks} $ is the number of knots and $ n_{order} = 4 $. The minimum dimension is therefore (for $ n_{breaks} = 1 $) $ n_{basis} = 3 $, and the maximum (for $ n_{breaks} = 51 $, corresponding to the number of original discrete data) $ n_{basis} = 53 $. However, in R, the value of $ n_{basis} $ must be at least $ n_{order} = 4 $, and for large values of $ n_{basis} $, overfitting of the model occurs, so we choose a maximum $ n_{basis} $ of a smaller number, say 43.
Code
k_cv <- 10 # k-fold CV
# values for the B-spline basis
rangeval <- range(t)
norder <- 4
n_basis_min <- norder
n_basis_max <- length(t) + norder - 2 - 10
dimensions <- n_basis_min:n_basis_max # all dimensions we want to test
# split training data into k parts
folds <- createMultiFolds(1:sum(split), k = k_cv, time = 1)
# list with three components ... matrices for each kernel -> linear, poly, radial
# empty matrix to hold results
# columns will have accuracy values for each part of the training set
# rows will have values for each dimension value
CV.results <- list(SVM.l = matrix(NA, nrow = length(dimensions), ncol = k_cv),
SVM.p = matrix(NA, nrow = length(dimensions), ncol = k_cv),
SVM.r = matrix(NA, nrow = length(dimensions), ncol = k_cv))
for (d in dimensions) {
# basis object
bbasis <- create.bspline.basis(rangeval = rangeval,
nbasis = d)
# projection of discrete data onto the B-spline basis of dimension d
Projection <- project.basis(y = XX, # matrix of discrete data
argvals = t, # vector of arguments
basisobj = bbasis) # basis object
# split into training and test data for CV
XX.train <- subset(t(Projection), split == TRUE)
for (index_cv in 1:k_cv) {
# definition of test and training parts for CV
fold <- folds[[index_cv]]
cv_sample <- 1:dim(XX.train)[1] %in% fold
data.projection.train.cv <- as.data.frame(XX.train[cv_sample, ])
data.projection.train.cv$Y <- factor(Y.train[cv_sample])
data.projection.test.cv <- as.data.frame(XX.train[!cv_sample, ])
Y.test.cv <- Y.train[!cv_sample]
data.projection.test.cv$Y <- factor(Y.test.cv)
# model construction
clf.SVM.l.projection <- svm(Y ~ ., data = data.projection.train.cv,
type = 'C-classification',
scale = TRUE,
kernel = 'linear')
clf.SVM.p.projection <- svm(Y ~ ., data = data.projection.train.cv,
type = 'C-classification',
scale = TRUE,
coef0 = 1,
kernel = 'polynomial')
clf.SVM.r.projection <- svm(Y ~ ., data = data.projection.train.cv,
type = 'C-classification',
scale = TRUE,
kernel = 'radial')
# accuracy on validation data
## linear kernel
predictions.test.l <- predict(clf.SVM.l.projection,
newdata = data.projection.test.cv)
presnost.test.l <- table(Y.test.cv, predictions.test.l) |>
prop.table() |> diag() |> sum()
## polynomial kernel
predictions.test.p <- predict(clf.SVM.p.projection,
newdata = data.projection.test.cv)
presnost.test.p <- table(Y.test.cv, predictions.test.p) |>
prop.table() |> diag() |> sum()
## radial kernel
predictions.test.r <- predict(clf.SVM.r.projection,
newdata = data.projection.test.cv)
presnost.test.r <- table(Y.test.cv, predictions.test.r) |>
prop.table() |> diag() |> sum()
# store accuracies for the given d and fold
CV.results$SVM.l[d - min(dimensions) + 1, index_cv] <- presnost.test.l
CV.results$SVM.p[d - min(dimensions) + 1, index_cv] <- presnost.test.p
CV.results$SVM.r[d - min(dimensions) + 1, index_cv] <- presnost.test.r
}
}
# calculate average accuracies for each d across folds
for (n_method in 1:length(CV.results)) {
CV.results[[n_method]] <- apply(CV.results[[n_method]], 1, mean)
}
d.opt <- c(which.max(CV.results$SVM.l) + n_basis_min - 1,
which.max(CV.results$SVM.p) + n_basis_min - 1,
which.max(CV.results$SVM.r) + n_basis_min - 1)
presnost.opt.cv <- c(max(CV.results$SVM.l),
max(CV.results$SVM.p),
max(CV.results$SVM.r))
data.frame(d_opt = d.opt, ERR = 1 - presnost.opt.cv,
row.names = c('linear', 'poly', 'radial'))## d_opt ERR
## linear 11 0.04306319
## poly 11 0.07699176
## radial 10 0.06449176We see that the best value for the parameter \(d\) is 11 for the linear kernel, with an error rate calculated using 10-fold CV of 0.0431, 11 for the polynomial kernel with an error rate of 0.077, and 10 for the radial kernel with an error rate of 0.0645.
For clarity, let’s plot the validation error rates as a function of the dimension \(d\).
Code
CV.results <- data.frame(d = dimensions |> rep(3),
CV = c(CV.results$SVM.l,
CV.results$SVM.p,
CV.results$SVM.r),
Kernel = rep(c('linear', 'polynomial', 'radial'),
each = length(dimensions)) |> factor())
CV.results |> ggplot(aes(x = d, y = 1 - CV, colour = Kernel)) +
geom_line(linetype = 'dashed') +
geom_point(size = 1.5) +
geom_point(data = data.frame(d.opt,
presnost.opt.cv),
aes(x = d.opt, y = 1 - presnost.opt.cv), colour = 'black', size = 2) +
theme_bw() +
labs(x = bquote(paste(d)),
y = 'Validation error') +
theme(legend.position = "bottom") +
scale_x_continuous(breaks = dimensions)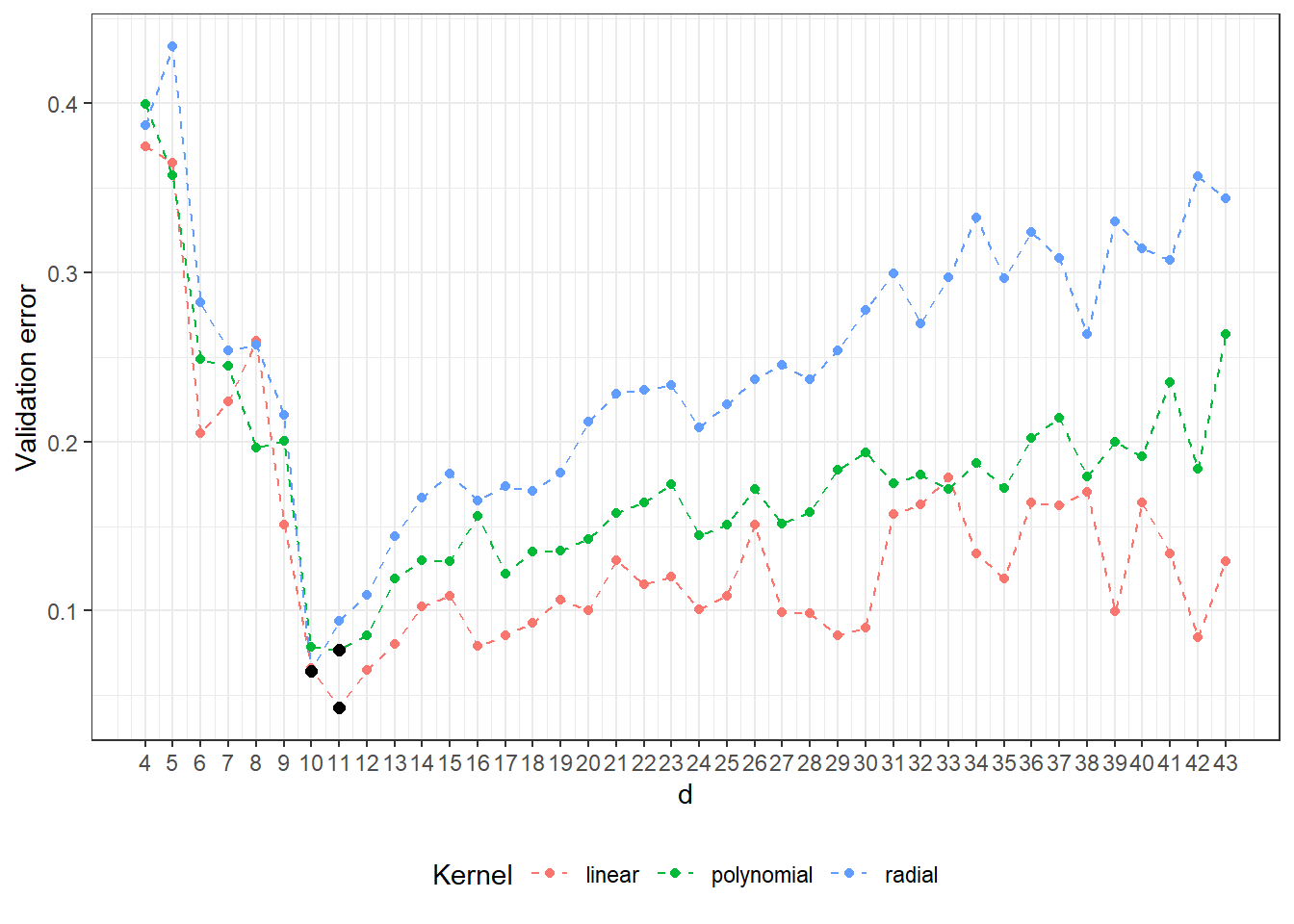
Figure 2.11: Dependency of validation error on the dimension of the subspace \(V_d\), separately for all three considered kernels in the SVM method. The optimal values of dimension \(V_d\) for individual kernel functions are marked with black points.
Now we can train individual classifiers on all training data and look at their performance on the test data. For each kernel function, we choose the dimension of the subspace onto which we project based on the results of cross-validation.
In the variable Projection, we have stored the matrix of coefficients from the orthogonal projection, that is,
\[ \texttt{Projection} = \begin{pmatrix} \langle x_1, \Psi_1 \rangle & \langle x_2, \Psi_1 \rangle & \cdots & \langle x_n, \Psi_1 \rangle\\ \langle x_1, \Psi_2 \rangle & \langle x_2, \Psi_2 \rangle & \cdots & \langle x_n, \Psi_2 \rangle\\ \vdots & \vdots & \ddots & \vdots \\ \langle x_1, \Psi_d \rangle & \langle x_2, \Psi_d \rangle & \dots & \langle x_n, \Psi_d \rangle \end{pmatrix}_{d \times n}. \]
Code
# Prepare a data table to store the results
Res <- data.frame(model = c('SVM linear - projection',
'SVM poly - projection',
'SVM rbf - projection'),
Err.train = NA,
Err.test = NA)
# Iterate over individual kernels
for (kernel_number in 1:3) {
kernel_type <- c('linear', 'polynomial', 'radial')[kernel_number]
# Basis object
bbasis <- create.bspline.basis(rangeval = rangeval,
nbasis = d.opt[kernel_number])
# Project discrete data onto the B-spline basis
Projection <- project.basis(y = XX, # matrix of discrete data
argvals = t, # vector of arguments
basisobj = bbasis) # basis object
# Split into training and test data
XX.train <- subset(t(Projection), split == TRUE)
XX.test <- subset(t(Projection), split == FALSE)
data.projection.train <- as.data.frame(XX.train)
data.projection.train$Y <- factor(Y.train)
data.projection.test <- as.data.frame(XX.test)
data.projection.test$Y <- factor(Y.test)
# Build the model
clf.SVM.projection <- svm(Y ~ ., data = data.projection.train,
type = 'C-classification',
scale = TRUE,
coef0 = 1,
kernel = kernel_type)
# Accuracy on training data
predictions.train <- predict(clf.SVM.projection, newdata = data.projection.train)
presnost.train <- table(Y.train, predictions.train) |>
prop.table() |> diag() |> sum()
# Accuracy on test data
predictions.test <- predict(clf.SVM.projection, newdata = data.projection.test)
presnost.test <- table(Y.test, predictions.test) |>
prop.table() |> diag() |> sum()
# Store results
Res[kernel_number, c(2, 3)] <- 1 - c(presnost.train, presnost.test)
}The error rate of the SVM method applied to the basis coefficients on the training data is therefore 4.29 % for the linear kernel, 3.57 % for the polynomial kernel, and 5 % for the Gaussian kernel. On the test data, the error rates are 10 % for the linear kernel, 8.33 % for the polynomial kernel, and 10 % for the radial kernel.
2.3.6.5 RKHS + SVM
2.3.6.5.0.1 Gaussian Kernel
Code
# remove the last column, which contains the values of Y
data.RKHS <- grid.data[, -dim(grid.data)[2]] |> t()
# also add test data
data.RKHS <- cbind(data.RKHS, grid.data.test[, -dim(grid.data.test)[2]] |> t())
# kernel and kernel matrix ... Gaussian with parameter gamma
Gauss.kernel <- function(x, y, gamma) {
return(exp(-gamma * norm(c(x - y) |> t(), type = 'F')))
}
Kernel.RKHS <- function(x, gamma) {
K <- matrix(NA, ncol = length(x), nrow = length(x))
for(i in 1:nrow(K)) {
for(j in 1:ncol(K)) {
K[i, j] <- Gauss.kernel(x = x[i], y = x[j], gamma = gamma)
}
}
return(K)
}Now let’s compute the matrix \(K_S\) and its eigenvalues and corresponding eigenvectors.
Code
To compute the coefficients in the representation of curves, that is, to compute the vectors \(\hat{\boldsymbol \lambda}_l^* = \left( \hat\lambda_{1l}^*, \dots, \hat\lambda_{\hat dl}^*\right)^\top, l = 1, 2, \dots, n\), we still need the coefficients from SVM. Unlike the classification problem, we are now solving a regression problem, as we are trying to express our observed curves in some (chosen by us using the kernel \(K\)) basis. Therefore, we will use the Support Vector Regression method, from which we will subsequently obtain the coefficients \(\alpha_{il}\).
Code
# determining coefficients alpha from SVM
alpha.RKHS <- matrix(0, nrow = dim(data.RKHS)[1],
ncol = dim(data.RKHS)[2]) # empty object
# model
for(i in 1:dim(data.RKHS)[2]) {
df.svm <- data.frame(x = t.seq,
y = data.RKHS[, i])
svm.RKHS <- svm(y ~ x, data = df.svm,
kernel = 'radial',
type = 'eps-regression',
epsilon = 0.1,
gamma = gamma)
# determining alpha
alpha.RKHS[svm.RKHS$index, i] <- svm.RKHS$coefs # replace zeros with coefficients
}Now we can compute the representations of the individual curves. First, let’s take \(\hat d\) as the full dimension, i.e., \(\hat d = m ={}\) 101, and then determine the optimal \(\hat d\) using cross-validation.
Code
# d
d.RKHS <- dim(alpha.RKHS)[1]
# determining the lambda vector
Lambda.RKHS <- matrix(NA,
ncol = dim(data.RKHS)[2],
nrow = d.RKHS) # create an empty object
# computation of the representation
for(l in 1:dim(data.RKHS)[2]) {
Lambda.RKHS[, l] <- (t(eig.vectors[, 1:d.RKHS]) %*% alpha.RKHS[, l]) * eig.vals[1:d.RKHS]
}Now we have stored the vectors \(\hat{\boldsymbol \lambda}_l^*, l = 1, 2, \dots, n\) for each curve in the columns of the matrix Lambda.RKHS. We will now use these vectors as the representation of the given curves and classify the data according to this discretization.
Code
# splitting into training and testing data
XX.train <- Lambda.RKHS[, 1:dim(grid.data)[1]]
XX.test <- Lambda.RKHS[, (dim(grid.data)[1] + 1):dim(Lambda.RKHS)[2]]
# preparing a data table to store results
Res <- data.frame(model = c('SVM linear - RKHS',
'SVM poly - RKHS',
'SVM rbf - RKHS'),
Err.train = NA,
Err.test = NA)
# iterating over individual kernels
for (kernel_number in 1:3) {
kernel_type <- c('linear', 'polynomial', 'radial')[kernel_number]
data.RKHS.train <- as.data.frame(t(XX.train))
data.RKHS.train$Y <- factor(Y.train)
data.RKHS.test <- as.data.frame(t(XX.test))
data.RKHS.test$Y <- factor(Y.test)
# building models
clf.SVM.RKHS <- svm(Y ~ ., data = data.RKHS.train,
type = 'C-classification',
scale = TRUE,
coef0 = 1,
kernel = kernel_type)
# accuracy on training data
predictions.train <- predict(clf.SVM.RKHS, newdata = data.RKHS.train)
accuracy.train <- table(Y.train, predictions.train) |>
prop.table() |> diag() |> sum()
# accuracy on testing data
predictions.test <- predict(clf.SVM.RKHS, newdata = data.RKHS.test)
accuracy.test <- table(Y.test, predictions.test) |>
prop.table() |> diag() |> sum()
# storing results
Res[kernel_number, c(2, 3)] <- 1 - c(accuracy.train, accuracy.test)
}| Model | \(\widehat{Err}_{train}\quad\quad\quad\quad\quad\) | \(\widehat{Err}_{test}\quad\quad\quad\quad\quad\) |
|---|---|---|
| SVM linear - RKHS | 0.1000 | 0.3833 |
| SVM poly - RKHS | 0.0286 | 0.3000 |
| SVM rbf - RKHS | 0.0786 | 0.2667 |
We can see that the model classifies the training data very well for all three kernels, while its performance on the test data is not good at all. It is evident that overfitting has occurred; therefore, we will use cross-validation to determine the optimal values of \(\gamma\) and \(d\).
Code
# splitting training data into k parts
folds <- createMultiFolds(1:sum(split), k = k_cv, time = 1)
# remove the last column, which contains the values of Y
data.RKHS <- grid.data[, -dim(grid.data)[2]] |> t()
# hyperparameter values that we will iterate over
dimensions <- 3:40 # reasonable range of values for d
gamma.cv <- 10^seq(-1, 2, length = 15)
# list with three components ... array for individual kernels -> linear, poly, radial
# empty matrix to store individual results
# columns will hold accuracy values for the respective gamma
# rows will hold values for the respective folds
dim.names <- list(gamma = paste0('gamma:', round(gamma.cv, 3)),
d = paste0('d:', dimensions),
CV = paste0('cv:', 1:k_cv))
CV.results <- list(
SVM.l = array(NA, dim = c(length(gamma.cv), length(dimensions), k_cv),
dimnames = dim.names),
SVM.p = array(NA, dim = c(length(gamma.cv), length(dimensions), k_cv),
dimnames = dim.names),
SVM.r = array(NA, dim = c(length(gamma.cv), length(dimensions), k_cv),
dimnames = dim.names))Code
# actual CV
for (gamma in gamma.cv) {
K <- Kernel.RKHS(t.seq, gamma = gamma)
Eig <- eigen(K)
eig.vals <- Eig$values
eig.vectors <- Eig$vectors
alpha.RKHS <- matrix(0, nrow = dim(data.RKHS)[1], ncol = dim(data.RKHS)[2])
# model
for(i in 1:dim(data.RKHS)[2]) {
df.svm <- data.frame(x = t.seq,
y = data.RKHS[, i])
svm.RKHS <- svm(y ~ x, data = df.svm,
kernel = 'radial',
type = 'eps-regression',
epsilon = 0.1,
gamma = gamma)
alpha.RKHS[svm.RKHS$index, i] <- svm.RKHS$coefs
}
# iterating over dimensions
for(d.RKHS in dimensions) {
Lambda.RKHS <- matrix(NA,
ncol = dim(data.RKHS)[2],
nrow = d.RKHS)
# compute representation
for(l in 1:dim(data.RKHS)[2]) {
Lambda.RKHS[, l] <- (t(eig.vectors[, 1:d.RKHS]) %*%
alpha.RKHS[, l]) * eig.vals[1:d.RKHS]
}
# iterate over folds
for (index_cv in 1:k_cv) {
# define test and training parts for CV
fold <- folds[[index_cv]]
# split into training and validation data
XX.train <- Lambda.RKHS[, fold]
XX.test <- Lambda.RKHS[, !(1:dim(Lambda.RKHS)[2] %in% fold)]
# prepare a data table to store results
Res <- data.frame(model = c('SVM linear - RKHS',
'SVM poly - RKHS',
'SVM rbf - RKHS'),
Err.test = NA)
# iterate over individual kernels
for (kernel_number in 1:3) {
kernel_type <- c('linear', 'polynomial', 'radial')[kernel_number]
data.RKHS.train <- as.data.frame(t(XX.train))
data.RKHS.train$Y <- factor(Y.train[fold])
data.RKHS.test <- as.data.frame(t(XX.test))
data.RKHS.test$Y <- factor(Y.train[!(1:dim(Lambda.RKHS)[2] %in% fold)])
# building models
clf.SVM.RKHS <- svm(Y ~ ., data = data.RKHS.train,
type = 'C-classification',
scale = TRUE,
coef0 = 1,
kernel = kernel_type)
# accuracy on validation data
predictions.test <- predict(clf.SVM.RKHS, newdata = data.RKHS.test)
accuracy.test <- table(data.RKHS.test$Y, predictions.test) |>
prop.table() |> diag() |> sum()
# storing results
Res[kernel_number, 2] <- 1 - accuracy.test
}
# store accuracies at positions for the respective d, gamma, and fold
CV.results$SVM.l[paste0('gamma:', round(gamma, 3)),
d.RKHS - min(dimensions) + 1,
index_cv] <- Res[1, 2]
CV.results$SVM.p[paste0('gamma:', round(gamma, 3)),
d.RKHS - min(dimensions) + 1,
index_cv] <- Res[2, 2]
CV.results$SVM.r[paste0('gamma:', round(gamma, 3)),
d.RKHS - min(dimensions) + 1,
index_cv] <- Res[3, 2]
}
}
}Code
# Calculate average accuracies for each method across folds
for (n_method in 1:length(CV.results)) {
CV.results[[n_method]] <- apply(CV.results[[n_method]], c(1, 2), mean)
}
gamma.opt <- c(which.min(CV.results$SVM.l) %% length(gamma.cv),
which.min(CV.results$SVM.p) %% length(gamma.cv),
which.min(CV.results$SVM.r) %% length(gamma.cv))
gamma.opt[gamma.opt == 0] <- length(gamma.cv)
gamma.opt <- gamma.cv[gamma.opt]
d.opt <- c(which.min(t(CV.results$SVM.l)) %% length(dimensions),
which.min(t(CV.results$SVM.p)) %% length(dimensions),
which.min(t(CV.results$SVM.r)) %% length(dimensions))
d.opt[d.opt == 0] <- length(dimensions)
d.opt <- dimensions[d.opt]
err.opt.cv <- c(min(CV.results$SVM.l),
min(CV.results$SVM.p),
min(CV.results$SVM.r))
df.RKHS.res <- data.frame(d = d.opt, gamma = gamma.opt, CV = err.opt.cv,
Kernel = c('linear', 'polynomial', 'radial') |> factor(),
row.names = c('linear', 'poly', 'radial'))| \(\quad\quad\quad\quad\quad d\) | \(\quad\quad\quad\quad\quad\gamma\) | \(\widehat{Err}_{cross\_validation}\) | Model | |
|---|---|---|---|---|
| linear | 10 | 13.8950 | 0.0630 | linear |
| poly | 19 | 22.7585 | 0.0912 | polynomial |
| radial | 40 | 0.4394 | 0.1016 | radial |
We see that the optimal parameter value is \(d={}\) 10 and \(\gamma={}\) 13.895 for the linear kernel, with an error rate computed using 10-fold CV of 0.063. For the polynomial kernel, \(d={}\) 19 and \(\gamma={}\) 22.7585 yield an error rate of 0.0912, and for the radial kernel, \(d={}\) 40 and \(\gamma={}\) 0.4394 yield an error rate of 0.1016.
For interest, let’s plot the validation error as a function of dimension \(d\) and the hyperparameter \(\gamma\).
Code
CV.results.plot <- data.frame(d = rep(dimensions |> rep(3), each = length(gamma.cv)),
gamma = rep(gamma.cv, length(dimensions)) |> rep(3),
CV = c(c(CV.results$SVM.l),
c(CV.results$SVM.p),
c(CV.results$SVM.r)),
Kernel = rep(c('linear', 'polynomial', 'radial'),
each = length(dimensions) *
length(gamma.cv)) |> factor())
CV.results.plot |>
ggplot(aes(x = d, y = gamma, z = CV)) +
geom_contour_filled() +
scale_y_continuous(trans='log10') +
facet_wrap(~Kernel) +
theme_bw() +
labs(x = expression(d),
y = expression(gamma)) +
scale_fill_brewer(palette = "Spectral") +
geom_point(data = df.RKHS.res, aes(x = d, y = gamma),
size = 5, pch = '+')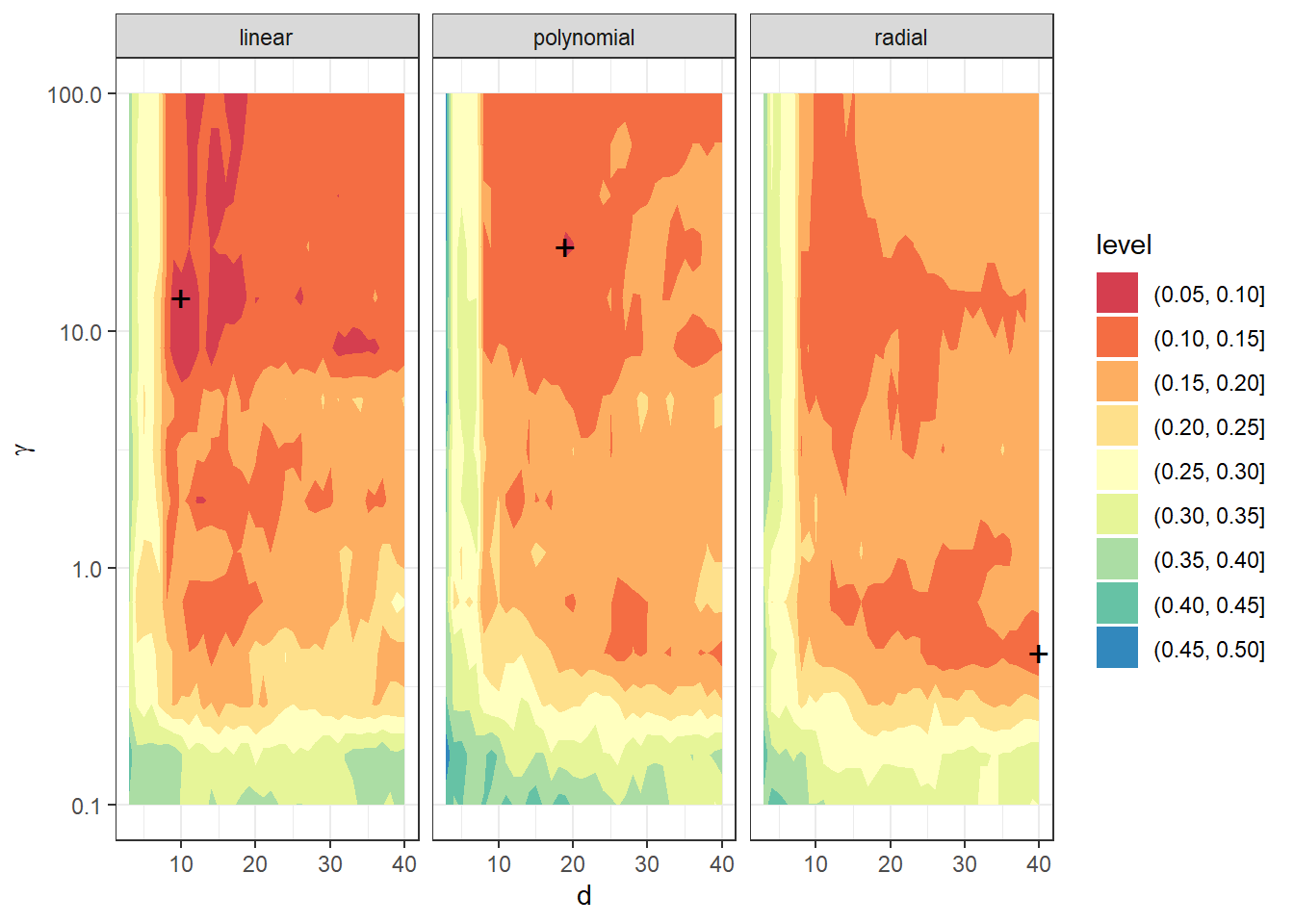
Figure 2.12: Dependence of validation error on the choice of hyperparameters \(d\) and \(\gamma\), separately for all three considered kernels in the SVM method.
Since we have already found the optimal hyperparameter values, we can construct the final models and determine their classification success on the test data.
Code
Code
# Prepare a data table to store results
Res <- data.frame(model = c('SVM linear - RKHS - radial',
'SVM poly - RKHS - radial',
'SVM rbf - RKHS - radial'),
Err.train = NA,
Err.test = NA)
# Iterate over the different kernels
for (kernel_number in 1:3) {
# Calculate the matrix K
gamma <- gamma.opt[kernel_number] # gamma value from CV
K <- Kernel.RKHS(t.seq, gamma = gamma)
# Determine eigenvalues and eigenvectors
Eig <- eigen(K)
eig.vals <- Eig$values
eig.vectors <- Eig$vectors
# Determine coefficients alpha from SVM
alpha.RKHS <- matrix(0, nrow = dim(data.RKHS)[1],
ncol = dim(data.RKHS)[2]) # empty object
# Model
for(i in 1:dim(data.RKHS)[2]) {
df.svm <- data.frame(x = t.seq,
y = data.RKHS[, i])
svm.RKHS <- svm(y ~ x, data = df.svm,
kernel = 'radial',
type = 'eps-regression',
epsilon = 0.1,
gamma = gamma)
# Determine alpha
alpha.RKHS[svm.RKHS$index, i] <- svm.RKHS$coefs # replace zeros with coefficients
}
# d
d.RKHS <- d.opt[kernel_number]
# Determine the lambda vector
Lambda.RKHS <- matrix(NA,
ncol = dim(data.RKHS)[2],
nrow = d.RKHS) # create an empty object
# Calculate representation
for(l in 1:dim(data.RKHS)[2]) {
Lambda.RKHS[, l] <- (t(eig.vectors[, 1:d.RKHS]) %*% alpha.RKHS[, l]) * eig.vals[1:d.RKHS]
}
# Split into training and test data
XX.train <- Lambda.RKHS[, 1:dim(grid.data)[1]]
XX.test <- Lambda.RKHS[, (dim(grid.data)[1] + 1):dim(Lambda.RKHS)[2]]
kernel_type <- c('linear', 'polynomial', 'radial')[kernel_number]
data.RKHS.train <- as.data.frame(t(XX.train))
data.RKHS.train$Y <- factor(Y.train)
data.RKHS.test <- as.data.frame(t(XX.test))
data.RKHS.test$Y <- factor(Y.test)
# Model construction
clf.SVM.RKHS <- svm(Y ~ ., data = data.RKHS.train,
type = 'C-classification',
scale = TRUE,
coef0 = 1,
kernel = kernel_type)
# Accuracy on training data
predictions.train <- predict(clf.SVM.RKHS, newdata = data.RKHS.train)
presnost.train <- table(Y.train, predictions.train) |>
prop.table() |> diag() |> sum()
# Accuracy on test data
predictions.test <- predict(clf.SVM.RKHS, newdata = data.RKHS.test)
presnost.test <- table(Y.test, predictions.test) |>
prop.table() |> diag() |> sum()
# Save results
Res[kernel_number, c(2, 3)] <- 1 - c(presnost.train, presnost.test)
}| Model | \(\widehat{Err}_{train}\quad\quad\quad\quad\quad\) | \(\widehat{Err}_{test}\quad\quad\quad\quad\quad\) |
|---|---|---|
| SVM linear - RKHS - radial | 0.0571 | 0.1333 |
| SVM poly - RKHS - radial | 0.0571 | 0.1667 |
| SVM rbf - RKHS - radial | 0.0143 | 0.1500 |
The error rate of the SVM method combined with projection onto the Reproducing Kernel Hilbert Space is therefore 5.71 % on the training data for the linear kernel, 5.71 % for the polynomial kernel, and 1.43 % for the Gaussian kernel. On the test data, the error rate of the method is 13.33 % for the linear kernel, 16.67 % for the polynomial kernel, and 15 % for the radial kernel.
2.3.7 Results Table
| Model | \(\widehat{Err}_{train}\quad\quad\quad\quad\quad\) | \(\widehat{Err}_{test}\quad\quad\quad\quad\quad\) |
|---|---|---|
| KNN | 0.3571 | 0.3833 |
| LDA | 0.4143 | 0.4000 |
| QDA | 0.3571 | 0.4000 |
| LR functional | 0.0357 | 0.0833 |
| RForest - discretization | 0.0000 | 0.3833 |
| RForest - score | 0.0357 | 0.4167 |
| RForest - Bbasis | 0.0000 | 0.4167 |
| SVM linear - discr | 0.0571 | 0.1667 |
| SVM poly - discr | 0.0214 | 0.1667 |
| SVM rbf - discr | 0.0357 | 0.1333 |
| SVM linear - PCA | 0.4429 | 0.4833 |
| SVM poly - PCA | 0.3786 | 0.4333 |
| SVM rbf - PCA | 0.3714 | 0.4000 |
| SVM linear - Bbasis | 0.0429 | 0.1000 |
| SVM poly - Bbasis | 0.0429 | 0.1167 |
| SVM rbf - Bbasis | 0.0714 | 0.1500 |
| SVM linear - projection | 0.0429 | 0.1000 |
| SVM poly - projection | 0.0357 | 0.0833 |
| SVM rbf - projection | 0.0500 | 0.1000 |
| SVM linear - RKHS - radial | 0.0571 | 0.1333 |
| SVM poly - RKHS - radial | 0.0571 | 0.1667 |
| SVM rbf - RKHS - radial | 0.0143 | 0.1500 |
2.4 Simulation Study
In the entire preceding section, we dealt with only one randomly generated dataset of functions from two classification classes, which we then randomly split into test and training parts. We evaluated the individual classifiers obtained using the considered methods based on test and training errors.
Since the generated data (and their division into two parts) can vary significantly with each repetition, the errors of individual classification algorithms will also vary significantly. Therefore, drawing any conclusions about the methods and comparing them with each other based on a single generated dataset can be very misleading.
For this reason, in this section, we will focus on repeating the entire previous procedure for various generated datasets. We will store the results in a table and ultimately calculate the average characteristics of the models across the individual repetitions. To make our conclusions sufficiently general, we will choose the number of repetitions to be \(n_{sim} = 25\).
Now, we will repeat the entire previous section \(n.sim\) times and store the error values in the object SIMUL_params, while varying the value of the parameter \(\sigma\) and observing how the results of the selected classification methods change with this value.
Code
# set seed for random number generation
set.seed(42)
# number of simulations for each value of the simulation parameter
n.sim <- 25
methods <- c('KNN', 'LDA', 'QDA', 'LR_functional',
'RF_discr', 'RF_score', 'RF_Bbasis',
'SVM linear - diskr', 'SVM poly - diskr', 'SVM rbf - diskr',
'SVM linear - PCA', 'SVM poly - PCA', 'SVM rbf - PCA',
'SVM linear - Bbasis', 'SVM poly - Bbasis',
'SVM rbf - Bbasis', 'SVM linear - projection',
'SVM poly - projection', 'SVM rbf - projection',
'SVM linear - RKHS - radial',
'SVM poly - RKHS - radial', 'SVM rbf - RKHS - radial'
)
# vector of standard deviations defining the variance around the generating curves
sigma_vector <- seq(0.1, 5, length = 30)
# resulting object to store simulation results
SIMUL_params <- array(data = NA, dim = c(length(methods), 4, length(sigma_vector)),
dimnames = list(
method = methods,
metric = c('ERRtrain', 'Errtest', 'SDtrain', 'SDtest'),
sigma = paste0(sigma_vector)))
for (n_sigma in 1:length(sigma_vector)) {
## list to store error values
# columns will represent methods
# rows will represent individual repetitions
# the list has two entries ... train and test
SIMULACE <- list(train = as.data.frame(matrix(NA, ncol = length(methods),
nrow = n.sim,
dimnames = list(1:n.sim, methods))),
test = as.data.frame(matrix(NA, ncol = length(methods),
nrow = n.sim,
dimnames = list(1:n.sim, methods))))
# object to store optimal hyperparameter values determined using CV
CV_RESULTS <- data.frame(KNN_K = rep(NA, n.sim),
nharm = NA,
LR_func_n_basis = NA,
SVM_d_Linear = NA,
SVM_d_Poly = NA,
SVM_d_Radial = NA)
## SIMULATIONS
for(sim in 1:n.sim) {
# number of generated observations for each class
n <- 100
# time vector evenly spaced on the interval [0, 6]
t <- seq(0, 6, length = 51)
# for Y = 0
X0 <- generate_values(t, funkce_0, n, sigma_vector[n_sigma], 2)
# for Y = 1
X1 <- generate_values(t, funkce_1, n, sigma_vector[n_sigma], 2)
rangeval <- range(t)
breaks <- t
norder <- 4
bbasis <- create.bspline.basis(rangeval = rangeval,
norder = norder,
breaks = breaks)
curv.Lfd <- int2Lfd(2)
# combine observations into one matrix
XX <- cbind(X0, X1)
lambda.vect <- 10^seq(from = -5, to = 3, length.out = 25) # lambda vector
gcv <- rep(NA, length = length(lambda.vect)) # empty vector to store GCV
for(index in 1:length(lambda.vect)) {
curv.Fdpar <- fdPar(bbasis, curv.Lfd, lambda.vect[index])
BSmooth <- smooth.basis(t, XX, curv.Fdpar) # smoothing
gcv[index] <- mean(BSmooth$gcv) # average over all observed curves
}
GCV <- data.frame(
lambda = round(log10(lambda.vect), 3),
GCV = gcv
)
# find the minimum value
lambda.opt <- lambda.vect[which.min(gcv)]
curv.fdPar <- fdPar(bbasis, curv.Lfd, lambda.opt)
BSmooth <- smooth.basis(t, XX, curv.fdPar)
XXfd <- BSmooth$fd
fdobjSmootheval <- eval.fd(fdobj = XXfd, evalarg = t)
# split into test and training parts
split <- sample.split(XXfd$fdnames$reps, SplitRatio = 0.7)
Y <- rep(c(0, 1), each = n)
X.train <- subset(XXfd, split == TRUE)
X.test <- subset(XXfd, split == FALSE)
Y.train <- subset(Y, split == TRUE)
Y.test <- subset(Y, split == FALSE)
x.train <- fdata(X.train)
y.train <- as.numeric(factor(Y.train))
## 1) K-Nearest Neighbors
k_cv <- 5 # k-fold CV
neighbours <- 1:15 # number of neighbors
# split the training data into k parts
folds <- createMultiFolds(X.train$fdnames$reps, k = k_cv, time = 1)
CV.results <- matrix(NA, nrow = length(neighbours), ncol = k_cv)
for (index in 1:k_cv) {
# define the index set
fold <- folds[[index]]
x.train.cv <- subset(X.train, c(1:length(X.train$fdnames$reps)) %in% fold) |>
fdata()
y.train.cv <- subset(Y.train, c(1:length(X.train$fdnames$reps)) %in% fold) |>
factor() |> as.numeric()
x.test.cv <- subset(X.train, !c(1:length(X.train$fdnames$reps)) %in% fold) |>
fdata()
y.test.cv <- subset(Y.train, !c(1:length(X.train$fdnames$reps)) %in% fold) |>
factor() |> as.numeric()
# projdeme kazdou cast ... k-krat zopakujeme
for(neighbour in neighbours) {
# model pro konkretni volbu K
neighb.model <- classif.knn(group = y.train.cv,
fdataobj = x.train.cv,
knn = neighbour)
# predikce na validacni casti
model.neighb.predict <- predict(neighb.model,
new.fdataobj = x.test.cv)
# presnost na validacni casti
presnost <- table(y.test.cv, model.neighb.predict) |>
prop.table() |> diag() |> sum()
# presnost vlozime na pozici pro dane K a fold
CV.results[neighbour, index] <- presnost
}
}
# spocitame prumerne presnosti pro jednotliva K pres folds
CV.results <- apply(CV.results, 1, mean)
K.opt <- which.max(CV.results)
CV_RESULTS$KNN_K[sim] <- K.opt
presnost.opt.cv <- max(CV.results)
CV.results <- data.frame(K = neighbours, CV = CV.results)
neighb.model <- classif.knn(group = y.train, fdataobj = x.train, knn = K.opt)
# predikce
model.neighb.predict <- predict(neighb.model,
new.fdataobj = fdata(X.test))
presnost <- table(as.numeric(factor(Y.test)), model.neighb.predict) |>
prop.table() |>
diag() |>
sum()
RESULTS <- data.frame(model = 'KNN',
Err.train = 1 - neighb.model$max.prob,
Err.test = 1 - presnost)
## 2) Lineární diskriminační analýza
# analyza hlavnich komponent
data.PCA <- pca.fd(X.train, nharm = 10) # nharm - maximalni pocet HK
nharm <- which(cumsum(data.PCA$varprop) >= 0.9)[1] # urceni p
CV_RESULTS$nharm[sim] <- nharm
if(nharm == 1) nharm <- 2
data.PCA <- pca.fd(X.train, nharm = nharm)
data.PCA.train <- as.data.frame(data.PCA$scores) # skore prvnich p HK
data.PCA.train$Y <- factor(Y.train) # prislusnost do trid
# vypocet skoru testovacich funkci
scores <- matrix(NA, ncol = nharm, nrow = length(Y.test)) # prazdna matice
for(k in 1:dim(scores)[1]) {
xfd = X.test[k] - data.PCA$meanfd[1] # k-te pozorovani - prumerna funkce
scores[k, ] = inprod(xfd, data.PCA$harmonics)
# skalarni soucin rezidua a vlastnich funkci rho (funkcionalni hlavni komponenty)
}
data.PCA.test <- as.data.frame(scores)
data.PCA.test$Y <- factor(Y.test)
colnames(data.PCA.test) <- colnames(data.PCA.train)
# model
clf.LDA <- lda(Y ~ ., data = data.PCA.train)
# presnost na trenovacich datech
predictions.train <- predict(clf.LDA, newdata = data.PCA.train)
presnost.train <- table(data.PCA.train$Y, predictions.train$class) |>
prop.table() |> diag() |> sum()
# presnost na trenovacich datech
predictions.test <- predict(clf.LDA, newdata = data.PCA.test)
presnost.test <- table(data.PCA.test$Y, predictions.test$class) |>
prop.table() |> diag() |> sum()
Res <- data.frame(model = 'LDA',
Err.train = 1 - presnost.train,
Err.test = 1 - presnost.test)
RESULTS <- rbind(RESULTS, Res)
## 3) Kvadratická diskriminační analýza
# model
clf.QDA <- qda(Y ~ ., data = data.PCA.train)
# presnost na trenovacich datech
predictions.train <- predict(clf.QDA, newdata = data.PCA.train)
presnost.train <- table(data.PCA.train$Y, predictions.train$class) |>
prop.table() |> diag() |> sum()
# presnost na trenovacich datech
predictions.test <- predict(clf.QDA, newdata = data.PCA.test)
presnost.test <- table(data.PCA.test$Y, predictions.test$class) |>
prop.table() |> diag() |> sum()
Res <- data.frame(model = 'QDA',
Err.train = 1 - presnost.train,
Err.test = 1 - presnost.test)
RESULTS <- rbind(RESULTS, Res)
## 4) Logistická regrese
### 4.1) Funkcionální logistická regrese
# vytvorime vhodne objekty
x.train <- fdata(X.train)
y.train <- as.numeric(Y.train)
# body, ve kterych jsou funkce vyhodnoceny
tt <- x.train[["argvals"]]
dataf <- as.data.frame(y.train)
colnames(dataf) <- "Y"
# B-spline baze
basis1 <- X.train$basis
### 10-fold cross-validation
n.basis.max <- 25
n.basis <- 4:n.basis.max
# k_cv <- 10 # k-fold CV
# rozdelime trenovaci data na k casti
folds <- createMultiFolds(X.train$fdnames$reps, k = k_cv, time = 1)
## prvky, ktere se behem cyklu nemeni
# body, ve kterych jsou funkce vyhodnoceny
tt <- x.train[["argvals"]]
rangeval <- range(tt)
# B-spline baze
basis1 <- X.train$basis
# vztah
f <- Y ~ x
# baze pro x
basis.x <- list("x" = basis1)
CV.results <- matrix(NA, nrow = length(n.basis), ncol = k_cv,
dimnames = list(n.basis, 1:k_cv))
for (index in 1:k_cv) {
# definujeme danou indexovou mnozinu
fold <- folds[[index]]
x.train.cv <- subset(X.train, c(1:length(X.train$fdnames$reps)) %in% fold) |>
fdata()
y.train.cv <- subset(Y.train, c(1:length(X.train$fdnames$reps)) %in% fold) |>
as.numeric()
x.test.cv <- subset(X.train, !c(1:length(X.train$fdnames$reps)) %in% fold) |>
fdata()
y.test.cv <- subset(Y.train, !c(1:length(X.train$fdnames$reps)) %in% fold) |>
as.numeric()
dataf <- as.data.frame(y.train.cv)
colnames(dataf) <- "Y"
for (i in n.basis) {
# baze pro bety
basis2 <- create.bspline.basis(rangeval = rangeval, nbasis = i)
basis.b <- list("x" = basis2)
# vstupni data do modelu
ldata <- list("df" = dataf, "x" = x.train.cv)
# binomicky model ... model logisticke regrese
model.glm <- fregre.glm(f, family = binomial(), data = ldata,
basis.x = basis.x, basis.b = basis.b)
# presnost na validacni casti
newldata = list("df" = as.data.frame(y.test.cv), "x" = x.test.cv)
predictions.valid <- predict(model.glm, newx = newldata)
predictions.valid <- data.frame(Y.pred = ifelse(predictions.valid < 1/2, 0, 1))
presnost.valid <- table(y.test.cv, predictions.valid$Y.pred) |>
prop.table() |> diag() |> sum()
# vlozime do matice
CV.results[as.character(i), as.character(index)] <- presnost.valid
}
}
# spocitame prumerne presnosti pro jednotliva n pres folds
CV.results <- apply(CV.results, 1, mean)
n.basis.opt <- n.basis[which.max(CV.results)]
CV_RESULTS$LR_func_n_basis[sim] <- n.basis.opt
presnost.opt.cv <- max(CV.results)
# optimalni model
basis2 <- create.bspline.basis(rangeval = range(tt), nbasis = n.basis.opt)
f <- Y ~ x
# baze pro x a bety
basis.x <- list("x" = basis1)
basis.b <- list("x" = basis2)
# vstupni data do modelu
dataf <- as.data.frame(y.train)
colnames(dataf) <- "Y"
ldata <- list("df" = dataf, "x" = x.train)
# binomicky model ... model logisticke regrese
model.glm <- fregre.glm(f, family = binomial(), data = ldata,
basis.x = basis.x, basis.b = basis.b)
# presnost na trenovacich datech
predictions.train <- predict(model.glm, newx = ldata)
predictions.train <- data.frame(Y.pred = ifelse(predictions.train < 1/2, 0, 1))
presnost.train <- table(Y.train, predictions.train$Y.pred) |>
prop.table() |> diag() |> sum()
# presnost na trenovacich datech
newldata = list("df" = as.data.frame(Y.test), "x" = fdata(X.test))
predictions.test <- predict(model.glm, newx = newldata)
predictions.test <- data.frame(Y.pred = ifelse(predictions.test < 1/2, 0, 1))
presnost.test <- table(Y.test, predictions.test$Y.pred) |>
prop.table() |> diag() |> sum()
Res <- data.frame(model = 'LR_functional',
Err.train = 1 - presnost.train,
Err.test = 1 - presnost.test)
RESULTS <- rbind(RESULTS, Res)
## 6) Náhodné lesy
### 6.1) Diskretizace intervalu
# posloupnost bodu, ve kterych funkce vyhodnotime
t.seq <- seq(0, 6, length = 101)
grid.data <- eval.fd(fdobj = X.train, evalarg = t.seq)
grid.data <- as.data.frame(t(grid.data)) # transpozice kvuli funkcim v radku
grid.data$Y <- Y.train |> factor()
grid.data.test <- eval.fd(fdobj = X.test, evalarg = t.seq)
grid.data.test <- as.data.frame(t(grid.data.test))
grid.data.test$Y <- Y.test |> factor()
# sestrojeni modelu
clf.RF <- randomForest(Y ~ ., data = grid.data,
ntree = 500, # pocet stromu
importance = TRUE,
nodesize = 5)
# presnost na trenovacich datech
predictions.train <- predict(clf.RF, newdata = grid.data)
presnost.train <- table(Y.train, predictions.train) |>
prop.table() |> diag() |> sum()
# presnost na trenovacich datech
predictions.test <- predict(clf.RF, newdata = grid.data.test)
presnost.test <- table(Y.test, predictions.test) |>
prop.table() |> diag() |> sum()
Res <- data.frame(model = 'RF_discr',
Err.train = 1 - presnost.train,
Err.test = 1 - presnost.test)
RESULTS <- rbind(RESULTS, Res)
### 6.2) Skóre hlavních komponent
# sestrojeni modelu
clf.RF.PCA <- randomForest(Y ~ ., data = data.PCA.train,
ntree = 500, # pocet stromu
importance = TRUE,
nodesize = 5)
# presnost na trenovacich datech
predictions.train <- predict(clf.RF.PCA, newdata = data.PCA.train)
presnost.train <- table(Y.train, predictions.train) |>
prop.table() |> diag() |> sum()
# presnost na trenovacich datech
predictions.test <- predict(clf.RF.PCA, newdata = data.PCA.test)
presnost.test <- table(Y.test, predictions.test) |>
prop.table() |> diag() |> sum()
Res <- data.frame(model = 'RF_score',
Err.train = 1 - presnost.train,
Err.test = 1 - presnost.test)
RESULTS <- rbind(RESULTS, Res)
### 6.3) Bázové koeficienty
# trenovaci dataset
data.Bbasis.train <- t(X.train$coefs) |> as.data.frame()
data.Bbasis.train$Y <- factor(Y.train)
# testovaci dataset
data.Bbasis.test <- t(X.test$coefs) |> as.data.frame()
data.Bbasis.test$Y <- factor(Y.test)
# sestrojeni modelu
clf.RF.Bbasis <- randomForest(Y ~ ., data = data.Bbasis.train,
ntree = 500, # pocet stromu
importance = TRUE,
nodesize = 5)
# presnost na trenovacich datech
predictions.train <- predict(clf.RF.Bbasis, newdata = data.Bbasis.train)
presnost.train <- table(Y.train, predictions.train) |>
prop.table() |> diag() |> sum()
# presnost na trenovacich datech
predictions.test <- predict(clf.RF.Bbasis, newdata = data.Bbasis.test)
presnost.test <- table(Y.test, predictions.test) |>
prop.table() |> diag() |> sum()
Res <- data.frame(model = 'RF_Bbasis',
Err.train = 1 - presnost.train,
Err.test = 1 - presnost.test)
RESULTS <- rbind(RESULTS, Res)
## 7) SVM
### 7.1) Diskretizace intervalu
# posloupnost bodu, ve kterych funkce vyhodnotime
t.seq <- seq(0, 6, length = 101)
# normovani dat
norms <- c()
for (i in 1:dim(XXfd$coefs)[2]) {
norms <- c(norms, as.numeric(1 / norm.fd(XXfd[i])))
}
XXfd_norm <- XXfd
XXfd_norm$coefs <- XXfd_norm$coefs * matrix(norms,
ncol = dim(XXfd$coefs)[2],
nrow = dim(XXfd$coefs)[1],
byrow = T)
# rozdeleni na testovaci a trenovaci cast
X.train_norm <- subset(XXfd_norm, split == TRUE)
X.test_norm <- subset(XXfd_norm, split == FALSE)
Y.train_norm <- subset(Y, split == TRUE)
Y.test_norm <- subset(Y, split == FALSE)
grid.data <- eval.fd(fdobj = X.train_norm, evalarg = t.seq)
grid.data <- as.data.frame(t(grid.data))
grid.data$Y <- Y.train_norm |> factor()
grid.data.test <- eval.fd(fdobj = X.test_norm, evalarg = t.seq)
grid.data.test <- as.data.frame(t(grid.data.test))
grid.data.test$Y <- Y.test_norm |> factor()
clf.SVM.l <- svm(Y ~ ., data = grid.data,
type = 'C-classification',
scale = TRUE,
cost = 100,
kernel = 'linear')
clf.SVM.p <- svm(Y ~ ., data = grid.data,
type = 'C-classification',
scale = TRUE,
coef0 = 1,
cost = 100,
kernel = 'polynomial')
clf.SVM.r <- svm(Y ~ ., data = grid.data,
type = 'C-classification',
scale = TRUE,
cost = 100000,
gamma = 0.0001,
kernel = 'radial')
# presnost na trenovacich datech
predictions.train.l <- predict(clf.SVM.l, newdata = grid.data)
presnost.train.l <- table(Y.train, predictions.train.l) |>
prop.table() |> diag() |> sum()
predictions.train.p <- predict(clf.SVM.p, newdata = grid.data)
presnost.train.p <- table(Y.train, predictions.train.p) |>
prop.table() |> diag() |> sum()
predictions.train.r <- predict(clf.SVM.r, newdata = grid.data)
presnost.train.r <- table(Y.train, predictions.train.r) |>
prop.table() |> diag() |> sum()
# presnost na testovacich datech
predictions.test.l <- predict(clf.SVM.l, newdata = grid.data.test)
presnost.test.l <- table(Y.test, predictions.test.l) |>
prop.table() |> diag() |> sum()
predictions.test.p <- predict(clf.SVM.p, newdata = grid.data.test)
presnost.test.p <- table(Y.test, predictions.test.p) |>
prop.table() |> diag() |> sum()
predictions.test.r <- predict(clf.SVM.r, newdata = grid.data.test)
presnost.test.r <- table(Y.test, predictions.test.r) |>
prop.table() |> diag() |> sum()
Res <- data.frame(model = c('SVM linear - diskr',
'SVM poly - diskr',
'SVM rbf - diskr'),
Err.train = 1 - c(presnost.train.l,
presnost.train.p, presnost.train.r),
Err.test = 1 - c(presnost.test.l,
presnost.test.p, presnost.test.r))
RESULTS <- rbind(RESULTS, Res)
### 7.2) Skóre hlavních komponent
# sestrojeni modelu
clf.SVM.l.PCA <- svm(Y ~ ., data = data.PCA.train,
type = 'C-classification',
scale = TRUE,
cost = 0.01,
kernel = 'linear')
clf.SVM.p.PCA <- svm(Y ~ ., data = data.PCA.train,
type = 'C-classification',
scale = TRUE,
coef0 = 1,
cost = 0.6,
kernel = 'polynomial')
clf.SVM.r.PCA <- svm(Y ~ ., data = data.PCA.train,
type = 'C-classification',
scale = TRUE,
cost = 1000,
gamma = 0.01,
kernel = 'radial')
# presnost na trenovacich datech
predictions.train.l <- predict(clf.SVM.l.PCA, newdata = data.PCA.train)
presnost.train.l <- table(data.PCA.train$Y, predictions.train.l) |>
prop.table() |> diag() |> sum()
predictions.train.p <- predict(clf.SVM.p.PCA, newdata = data.PCA.train)
presnost.train.p <- table(data.PCA.train$Y, predictions.train.p) |>
prop.table() |> diag() |> sum()
predictions.train.r <- predict(clf.SVM.r.PCA, newdata = data.PCA.train)
presnost.train.r <- table(data.PCA.train$Y, predictions.train.r) |>
prop.table() |> diag() |> sum()
# presnost na testovacich datech
predictions.test.l <- predict(clf.SVM.l.PCA, newdata = data.PCA.test)
presnost.test.l <- table(data.PCA.test$Y, predictions.test.l) |>
prop.table() |> diag() |> sum()
predictions.test.p <- predict(clf.SVM.p.PCA, newdata = data.PCA.test)
presnost.test.p <- table(data.PCA.test$Y, predictions.test.p) |>
prop.table() |> diag() |> sum()
predictions.test.r <- predict(clf.SVM.r.PCA, newdata = data.PCA.test)
presnost.test.r <- table(data.PCA.test$Y, predictions.test.r) |>
prop.table() |> diag() |> sum()
Res <- data.frame(model = c('SVM linear - PCA',
'SVM poly - PCA',
'SVM rbf - PCA'),
Err.train = 1 - c(presnost.train.l,
presnost.train.p, presnost.train.r),
Err.test = 1 - c(presnost.test.l,
presnost.test.p, presnost.test.r))
RESULTS <- rbind(RESULTS, Res)
### 7.3) Bázové koeficienty
# sestrojeni modelu
clf.SVM.l.Bbasis <- svm(Y ~ ., data = data.Bbasis.train,
type = 'C-classification',
scale = TRUE,
cost = 500,
kernel = 'linear')
clf.SVM.p.Bbasis <- svm(Y ~ ., data = data.Bbasis.train,
type = 'C-classification',
scale = TRUE,
coef0 = 1,
cost = 500,
kernel = 'polynomial')
clf.SVM.r.Bbasis <- svm(Y ~ ., data = data.Bbasis.train,
type = 'C-classification',
scale = TRUE,
cost = 1000,
gamma = 0.005,
kernel = 'radial')
# presnost na trenovacich datech
predictions.train.l <- predict(clf.SVM.l.Bbasis, newdata = data.Bbasis.train)
presnost.train.l <- table(Y.train, predictions.train.l) |>
prop.table() |> diag() |> sum()
predictions.train.p <- predict(clf.SVM.p.Bbasis, newdata = data.Bbasis.train)
presnost.train.p <- table(Y.train, predictions.train.p) |>
prop.table() |> diag() |> sum()
predictions.train.r <- predict(clf.SVM.r.Bbasis, newdata = data.Bbasis.train)
presnost.train.r <- table(Y.train, predictions.train.r) |>
prop.table() |> diag() |> sum()
# presnost na trenovacich datech
predictions.test.l <- predict(clf.SVM.l.Bbasis, newdata = data.Bbasis.test)
presnost.test.l <- table(Y.test, predictions.test.l) |>
prop.table() |> diag() |> sum()
predictions.test.p <- predict(clf.SVM.p.Bbasis, newdata = data.Bbasis.test)
presnost.test.p <- table(Y.test, predictions.test.p) |>
prop.table() |> diag() |> sum()
predictions.test.r <- predict(clf.SVM.r.Bbasis, newdata = data.Bbasis.test)
presnost.test.r <- table(Y.test, predictions.test.r) |>
prop.table() |> diag() |> sum()
Res <- data.frame(model = c('SVM linear - Bbasis',
'SVM poly - Bbasis',
'SVM rbf - Bbasis'),
Err.train = 1 - c(presnost.train.l,
presnost.train.p, presnost.train.r),
Err.test = 1 - c(presnost.test.l,
presnost.test.p, presnost.test.r))
RESULTS <- rbind(RESULTS, Res)
### 7.4) Projekce na B-splinovou bázi
# hodnoty pro B-splinovou bazi
rangeval <- range(t)
norder <- 4
n_basis_min <- norder
n_basis_max <- 20 # length(t) + norder - 2 - 10
dimensions <- n_basis_min:n_basis_max
folds <- createMultiFolds(1:sum(split), k = k_cv, time = 1)
CV.results <- list(SVM.l = matrix(NA, nrow = length(dimensions), ncol = k_cv),
SVM.p = matrix(NA, nrow = length(dimensions), ncol = k_cv),
SVM.r = matrix(NA, nrow = length(dimensions), ncol = k_cv))
for (d in dimensions) {
bbasis <- create.bspline.basis(rangeval = rangeval,
nbasis = d)
Projection <- project.basis(y = XX, argvals = t, basisobj = bbasis)
XX.train <- subset(t(Projection), split == TRUE)
for (index_cv in 1:k_cv) {
fold <- folds[[index_cv]]
cv_sample <- 1:dim(XX.train)[1] %in% fold
data.projection.train.cv <- as.data.frame(XX.train[cv_sample, ])
data.projection.train.cv$Y <- factor(Y.train[cv_sample])
data.projection.test.cv <- as.data.frame(XX.train[!cv_sample, ])
Y.test.cv <- Y.train[!cv_sample]
data.projection.test.cv$Y <- factor(Y.test.cv)
# sestrojeni modelu
clf.SVM.l.projection <- svm(Y ~ ., data = data.projection.train.cv,
type = 'C-classification',
scale = TRUE,
kernel = 'linear')
clf.SVM.p.projection <- svm(Y ~ ., data = data.projection.train.cv,
type = 'C-classification',
scale = TRUE,
coef0 = 1,
kernel = 'polynomial')
clf.SVM.r.projection <- svm(Y ~ ., data = data.projection.train.cv,
type = 'C-classification',
scale = TRUE,
kernel = 'radial')
# presnost na validacnich datech
## linear kernel
predictions.test.l <- predict(clf.SVM.l.projection,
newdata = data.projection.test.cv)
presnost.test.l <- table(Y.test.cv, predictions.test.l) |>
prop.table() |> diag() |> sum()
## polynomial kernel
predictions.test.p <- predict(clf.SVM.p.projection,
newdata = data.projection.test.cv)
presnost.test.p <- table(Y.test.cv, predictions.test.p) |>
prop.table() |> diag() |> sum()
## radial kernel
predictions.test.r <- predict(clf.SVM.r.projection,
newdata = data.projection.test.cv)
presnost.test.r <- table(Y.test.cv, predictions.test.r) |>
prop.table() |> diag() |> sum()
# presnosti vlozime na pozice pro dane d a fold
CV.results$SVM.l[d - min(dimensions) + 1, index_cv] <- presnost.test.l
CV.results$SVM.p[d - min(dimensions) + 1, index_cv] <- presnost.test.p
CV.results$SVM.r[d - min(dimensions) + 1, index_cv] <- presnost.test.r
}
}
# spocitame prumerne presnosti pro jednotliva d pres folds
for (n_method in 1:length(CV.results)) {
CV.results[[n_method]] <- apply(CV.results[[n_method]], 1, mean)
}
d.opt <- c(which.max(CV.results$SVM.l) + n_basis_min - 1,
which.max(CV.results$SVM.p) + n_basis_min - 1,
which.max(CV.results$SVM.r) + n_basis_min - 1)
# ulozime optimalni d do datove tabulky
CV_RESULTS[sim, 4:6] <- d.opt
# pripravime si datovou tabulku pro ulozeni vysledku
Res <- data.frame(model = c('SVM linear - projection',
'SVM poly - projection',
'SVM rbf - projection'),
Err.train = NA,
Err.test = NA)
for (kernel_number in 1:3) {
kernel_type <- c('linear', 'polynomial', 'radial')[kernel_number]
bbasis <- create.bspline.basis(rangeval = rangeval,
nbasis = d.opt[kernel_number])
Projection <- project.basis(y = XX, argvals = t, basisobj = bbasis)
XX.train <- subset(t(Projection), split == TRUE)
XX.test <- subset(t(Projection), split == FALSE)
data.projection.train <- as.data.frame(XX.train)
data.projection.train$Y <- factor(Y.train)
data.projection.test <- as.data.frame(XX.test)
data.projection.test$Y <- factor(Y.test)
# sestrojeni modelu
clf.SVM.projection <- svm(Y ~ ., data = data.projection.train,
type = 'C-classification',
scale = TRUE,
coef0 = 1,
kernel = kernel_type)
# presnost na trenovacich datech
predictions.train <- predict(clf.SVM.projection, newdata = data.projection.train)
presnost.train <- table(Y.train, predictions.train) |>
prop.table() |> diag() |> sum()
# presnost na trenovacich datech
predictions.test <- predict(clf.SVM.projection, newdata = data.projection.test)
presnost.test <- table(Y.test, predictions.test) |>
prop.table() |> diag() |> sum()
# ulozeni vysledku
Res[kernel_number, c(2, 3)] <- 1 - c(presnost.train, presnost.test)
}
RESULTS <- rbind(RESULTS, Res)
## 7.5) SVM + RKHS
### Gaussovo jadro
# # jadro a jadrova matice ... Gaussovske s parametrem gamma
# Gauss.kernel <- function(x, y, gamma) {
# return(exp(-gamma * norm(c(x - y) |> t(), type = 'F')))
# }
#
# Kernel.RKHS <- function(x, gamma) {
# K <- matrix(NA, ncol = length(x), nrow = length(x))
# for(i in 1:nrow(K)) {
# for(j in 1:ncol(K)) {
# K[i, j] <- Gauss.kernel(x = x[i], y = x[j], gamma = gamma)
# }
# }
# return(K)
# }
# rozdelime trenovaci data na k casti
folds <- createMultiFolds(1:sum(split), k = k_cv, time = 1)
# odstranime posledni sloupec, ve kterem jsou hodnoty Y
data.RKHS <- grid.data[, -dim(grid.data)[2]] |> t()
# hodnoty hyperparametru, ktere budeme prochazet
dimensions <- seq(10, 40, by = 5) # rozumny rozsah hodnot d
gamma.cv <- 10^seq(-2, 2, length = 5)
# list se tremi slozkami ... array pro jednotlive jadra -> linear, poly, radial
# prazdna matice, do ktere vlozime jednotlive vysledky
# ve sloupcich budou hodnoty presnosti pro dane
# v radcich budou hodnoty pro danou gamma a vrstvy odpovidaji folds
dim.names <- list(gamma = paste0('gamma:', round(gamma.cv, 3)),
d = paste0('d:', dimensions),
CV = paste0('cv:', 1:k_cv))
CV.results <- list(
SVM.l = array(NA, dim = c(length(gamma.cv), length(dimensions), k_cv),
dimnames = dim.names),
SVM.p = array(NA, dim = c(length(gamma.cv), length(dimensions), k_cv),
dimnames = dim.names),
SVM.r = array(NA, dim = c(length(gamma.cv), length(dimensions), k_cv),
dimnames = dim.names))
# samotna CV
for (gamma in gamma.cv) {
K <- Kernel.RKHS(t.seq, gamma = gamma)
Eig <- eigen(K)
eig.vals <- Eig$values
eig.vectors <- Eig$vectors
alpha.RKHS <- matrix(0, nrow = dim(data.RKHS)[1], ncol = dim(data.RKHS)[2])
# model
for(i in 1:dim(data.RKHS)[2]) {
df.svm <- data.frame(x = t.seq,
y = data.RKHS[, i])
svm.RKHS <- svm(y ~ x, data = df.svm,
kernel = 'radial',
type = 'eps-regression',
epsilon = 0.1,
gamma = gamma)
alpha.RKHS[svm.RKHS$index, i] <- svm.RKHS$coefs
}
# projdeme dimenze
for(d.RKHS in dimensions) {
Lambda.RKHS <- matrix(NA,
ncol = dim(data.RKHS)[2],
nrow = d.RKHS)
# vypocet reprezentace
for(l in 1:dim(data.RKHS)[2]) {
Lambda.RKHS[, l] <- (t(eig.vectors[, 1:d.RKHS]) %*%
alpha.RKHS[, l]) * eig.vals[1:d.RKHS]
}
# projdeme folds
for (index_cv in 1:k_cv) {
# definice testovaci a trenovaci casti pro CV
fold <- folds[[index_cv]]
# rozdeleni na trenovaci a validacni data
XX.train <- Lambda.RKHS[, fold]
XX.test <- Lambda.RKHS[, !(1:dim(Lambda.RKHS)[2] %in% fold)]
# pripravime si datovou tabulku pro ulozeni vysledku
Res <- data.frame(model = c('SVM linear - RKHS',
'SVM poly - RKHS',
'SVM rbf - RKHS'),
Err.test = NA)
# projdeme jednotliva jadra
for (kernel_number in 1:3) {
kernel_type <- c('linear', 'polynomial', 'radial')[kernel_number]
data.RKHS.train <- as.data.frame(t(XX.train))
data.RKHS.train$Y <- factor(Y.train[fold])
data.RKHS.test <- as.data.frame(t(XX.test))
data.RKHS.test$Y <- factor(Y.train[!(1:dim(Lambda.RKHS)[2] %in% fold)])
# sestrojeni modelu
clf.SVM.RKHS <- svm(Y ~ ., data = data.RKHS.train,
type = 'C-classification',
scale = TRUE,
coef0 = 1,
kernel = kernel_type)
# presnost na validacnich datech
predictions.test <- predict(clf.SVM.RKHS, newdata = data.RKHS.test)
presnost.test <- table(data.RKHS.test$Y, predictions.test) |>
prop.table() |> diag() |> sum()
# ulozeni vysledku
Res[kernel_number, 2] <- 1 - presnost.test
}
# presnosti vlozime na pozice pro dane d, gamma a fold
CV.results$SVM.l[paste0('gamma:', round(gamma, 3)),
paste0('d:', d.RKHS),
index_cv] <- Res[1, 2]
CV.results$SVM.p[paste0('gamma:', round(gamma, 3)),
paste0('d:', d.RKHS),
index_cv] <- Res[2, 2]
CV.results$SVM.r[paste0('gamma:', round(gamma, 3)),
paste0('d:', d.RKHS),
index_cv] <- Res[3, 2]
}
}
}
# spocitame prumerne presnosti pro jednotliva d pres folds
for (n_method in 1:length(CV.results)) {
CV.results[[n_method]] <- apply(CV.results[[n_method]], c(1, 2), mean)
}
gamma.opt <- c(which.min(CV.results$SVM.l) %% length(gamma.cv),
which.min(CV.results$SVM.p) %% length(gamma.cv),
which.min(CV.results$SVM.r) %% length(gamma.cv))
gamma.opt[gamma.opt == 0] <- length(gamma.cv)
gamma.opt <- gamma.cv[gamma.opt]
d.opt <- c(which.min(t(CV.results$SVM.l)) %% length(dimensions),
which.min(t(CV.results$SVM.p)) %% length(dimensions),
which.min(t(CV.results$SVM.r)) %% length(dimensions))
d.opt[d.opt == 0] <- length(dimensions)
d.opt <- dimensions[d.opt]
err.opt.cv <- c(min(CV.results$SVM.l),
min(CV.results$SVM.p),
min(CV.results$SVM.r))
df.RKHS.res <- data.frame(d = d.opt, gamma = gamma.opt, CV = err.opt.cv,
Kernel = c('linear', 'polynomial', 'radial') |> factor(),
row.names = c('linear', 'poly', 'radial'))
# CV_RESULTS$SVM_RKHS_radial_gamma[sim] <- gamma.opt
# CV_RESULTS$SVM_RKHS_radial_d[sim] <- d.opt
# odstranime posledni sloupec, ve kterem jsou hodnoty Y
data.RKHS <- grid.data[, -dim(grid.data)[2]] |> t()
# pridame i testovaci data
data.RKHS <- cbind(data.RKHS, grid.data.test[, -dim(grid.data.test)[2]] |> t())
# pripravime si datovou tabulku pro ulozeni vysledku
Res <- data.frame(model = c('SVM linear - RKHS - radial',
'SVM poly - RKHS - radial',
'SVM rbf - RKHS - radial'),
Err.train = NA,
Err.test = NA)
# projdeme jednotliva jadra
for (kernel_number in 1:3) {
# spocitame matici K
gamma <- gamma.opt[kernel_number] # hodnota gamma pomoci CV
K <- Kernel.RKHS(t.seq, gamma = gamma)
# urcime vlastni cisla a vektory
Eig <- eigen(K)
eig.vals <- Eig$values
eig.vectors <- Eig$vectors
# urceni koeficientu alpha z SVM
alpha.RKHS <- matrix(0, nrow = dim(data.RKHS)[1],
ncol = dim(data.RKHS)[2]) # prazdny objekt
# model
for(i in 1:dim(data.RKHS)[2]) {
df.svm <- data.frame(x = t.seq,
y = data.RKHS[, i])
svm.RKHS <- svm(y ~ x, data = df.svm,
kernel = 'radial',
type = 'eps-regression',
epsilon = 0.1,
gamma = gamma)
# urceni alpha
alpha.RKHS[svm.RKHS$index, i] <- svm.RKHS$coefs # nahrazeni nul koeficienty
}
# d
d.RKHS <- d.opt[kernel_number]
# urceni vektoru lambda
Lambda.RKHS <- matrix(NA,
ncol = dim(data.RKHS)[2],
nrow = d.RKHS) # vytvoreni prazdneho objektu
# vypocet reprezentace
for(l in 1:dim(data.RKHS)[2]) {
Lambda.RKHS[, l] <- (t(eig.vectors[, 1:d.RKHS]) %*% alpha.RKHS[, l]) * eig.vals[1:d.RKHS]
}
# rozdeleni na trenovaci a testovaci data
XX.train <- Lambda.RKHS[, 1:dim(grid.data)[1]]
XX.test <- Lambda.RKHS[, (dim(grid.data)[1] + 1):dim(Lambda.RKHS)[2]]
kernel_type <- c('linear', 'polynomial', 'radial')[kernel_number]
data.RKHS.train <- as.data.frame(t(XX.train))
data.RKHS.train$Y <- factor(Y.train)
data.RKHS.test <- as.data.frame(t(XX.test))
data.RKHS.test$Y <- factor(Y.test)
# sestrojeni modelu
clf.SVM.RKHS <- svm(Y ~ ., data = data.RKHS.train,
type = 'C-classification',
scale = TRUE,
coef0 = 1,
kernel = kernel_type)
# presnost na trenovacich datech
predictions.train <- predict(clf.SVM.RKHS, newdata = data.RKHS.train)
presnost.train <- table(Y.train, predictions.train) |>
prop.table() |> diag() |> sum()
# presnost na testovacich datech
predictions.test <- predict(clf.SVM.RKHS, newdata = data.RKHS.test)
presnost.test <- table(Y.test, predictions.test) |>
prop.table() |> diag() |> sum()
# ulozeni vysledku
Res[kernel_number, c(2, 3)] <- 1 - c(presnost.train, presnost.test)
}
RESULTS <- rbind(RESULTS, Res)
## pridame vysledky do objektu SIMULACE
SIMULACE$train[sim, ] <- RESULTS$Err.train
SIMULACE$test[sim, ] <- RESULTS$Err.test
cat('\r', paste0(n_sigma, ': ', sim))
}
# Nyní spočítáme průměrné testovací a trénovací chybovosti pro jednotlivé klasifikační metody.
# dame do vysledne tabulky
SIMULACE.df <- data.frame(Err.train = apply(SIMULACE$train, 2, mean),
Err.test = apply(SIMULACE$test, 2, mean),
SD.train = apply(SIMULACE$train, 2, sd),
SD.test = apply(SIMULACE$test, 2, sd))
SIMUL_params[, , n_sigma] <- as.matrix(SIMULACE.df)
}
# ulozime vysledne hodnoty
save(SIMUL_params, file = 'RData/simulace_parametry_sigma_03_rf_cv.RData')2.4.1 Graphical Output
Let’s look at the dependence of simulated results on the value of the standard deviation parameter of the normal distribution for measurement errors. First, let’s plot the data for training errors.
Code
# for training data
SIMUL_params[, 1, ] |>
as.data.frame() |>
mutate(method = methods) |>
pivot_longer(cols = as.character(sigma_vector),
names_to = 'sigma',
values_to = 'Err') |>
mutate(method = factor(method, levels = methods, labels = methods, ordered = TRUE),
sigma = as.numeric(sigma)) |>
ggplot(aes(x = sigma, y = Err, colour = method)) +
geom_line() +
theme_bw() +
labs(x = expression(sigma[x]),
y = expression(widehat(Err)[test]),
colour = 'Classification Method') +
theme(legend.position = 'bottom')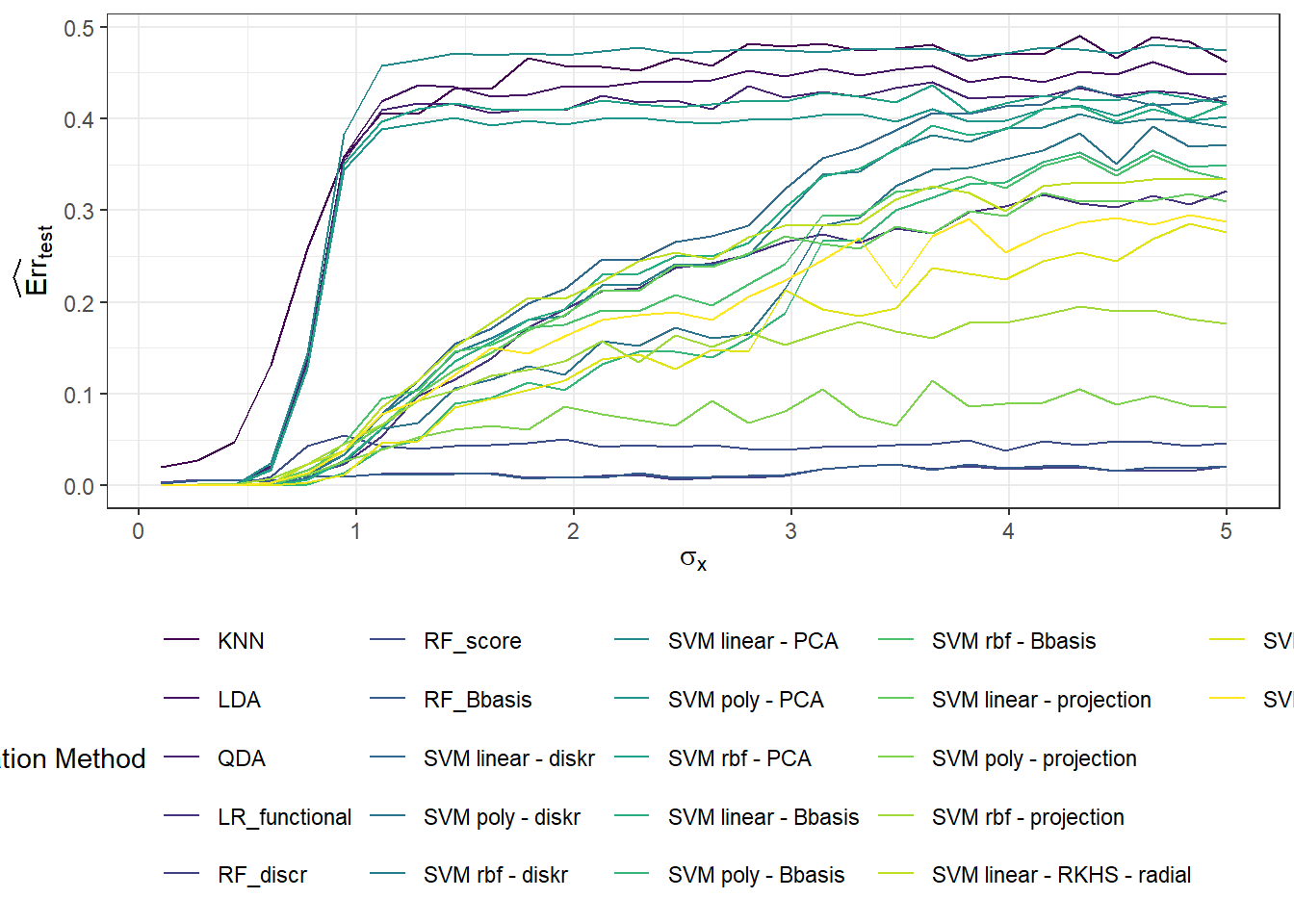
Figure 2.13: Graph of the dependence of training error for individual classification methods on the value of the parameter \(\sigma_{x}\), which defines the standard deviation for generating random deviations around the generating curves.
Next, for test errors.
Code
# for test data
SIMUL_params[, 2, ] |>
as.data.frame() |>
mutate(method = methods) |>
pivot_longer(cols = as.character(sigma_vector),
names_to = 'sigma',
values_to = 'Err') |>
mutate(method = factor(method, levels = methods, labels = methods, ordered = TRUE),
sigma = as.numeric(sigma)) |>
ggplot(aes(x = sigma, y = Err, colour = method)) +
geom_line() +
theme_bw() +
labs(x = expression(sigma[x]),
y = expression(widehat(Err)[test]),
colour = 'Classification Method') +
theme(legend.position = 'bottom')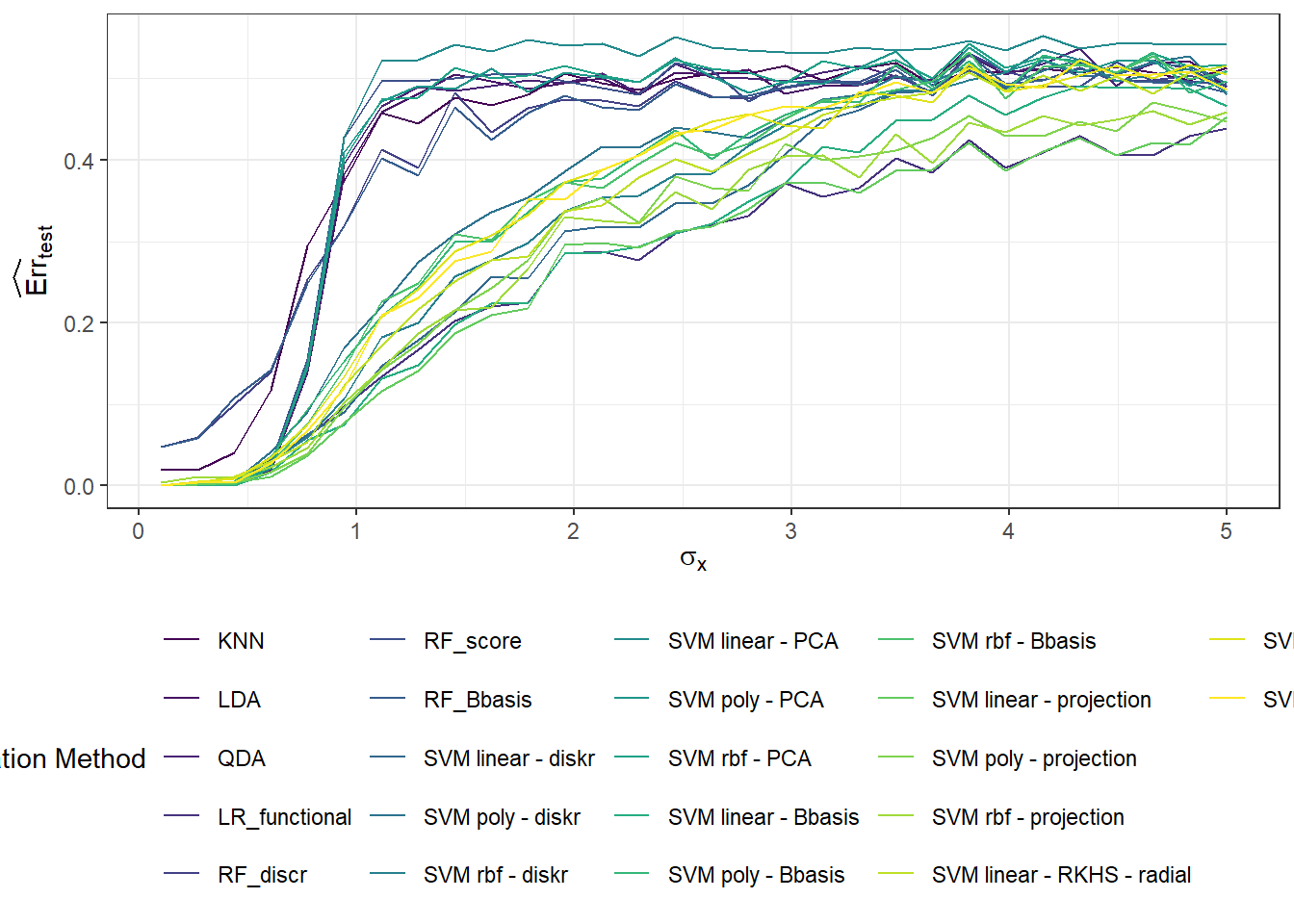
Figure 2.14: Graph of the dependence of test error for individual classification methods on the value of the parameter \(\sigma_{x}\), which defines the standard deviation for generating random deviations around the generating curves.
Since the results are affected by random deviations, and increasing the number of repetitions n.sim would be computationally intensive, let’s now smooth the curves of the average test and training errors. Since the error is a non-negative quantity, we will smooth the curves with this in mind. Additionally, to ensure that the smoothed curves closely follow the observed discrete values, we consider a different weight for small and large values of \(\sigma\).
Code
methods_subset <- c('KNN', 'LR_functional', 'RF_Bbasis', 'SVM linear - diskr',
'SVM linear - PCA', 'SVM linear - Bbasis',
'SVM linear - projection', 'SVM linear - RKHS - radial')
Dat <- SIMUL_params[, 1, ] |>
as.data.frame() |> t()
breaks <- sigma_vector
rangeval <- range(breaks)
norder <- 4
bbasis <- create.bspline.basis(rangeval = rangeval,
norder = norder,
breaks = breaks)
curv.Lfd <- int2Lfd(2)
lambda.opt <- 1e-4
curv.fdPar <- fdPar(bbasis, curv.Lfd, lambda.opt)
BSmooth <- smooth.pos(breaks, Dat, curv.fdPar, dbglev = 0,
wtvec = c(rep(1000, 5), rep(8, 5), rep(1, 20))) # smooth.posCode
XXfd <- BSmooth$Wfdobj # Wfdobj
fdobjSmootheval <- eval.posfd(Wfdobj = XXfd, # eval.posfd
evalarg = seq(min(sigma_vector), max(sigma_vector),
length = 101))
df_plot_smooth <- data.frame(
method = rep(methods, each = dim(fdobjSmootheval)[1]),
value = c(fdobjSmootheval),
sigma = rep(seq(min(sigma_vector), max(sigma_vector), length = 101), length(methods))
) |>
filter(method %in% methods_subset) |>
mutate(method = factor(method, levels = methods_subset,
labels = methods_subset, ordered = TRUE)) To enhance clarity, we will plot the graphs only for a subset of methods.
Code
Code
# for test data
SIMUL_params[, 1, ] |>
as.data.frame() |>
mutate(method = methods) |>
pivot_longer(cols = as.character(sigma_vector),
names_to = 'sigma',
values_to = 'Err') |>
mutate(method = factor(method, levels = methods, labels = methods, ordered = TRUE),
sigma = as.numeric(sigma)) |>
filter(method %in% methods_subset) |>
mutate(method = factor(method, levels = methods_subset,
labels = methods_subset, ordered = TRUE)) |>
ggplot(aes(x = sigma, y = Err, colour = method, shape = method)) +
geom_point(alpha = 0.7, size = 0.6) +
theme_bw() +
labs(x = 'sigma',
y = 'Test Error',
colour = 'Classification Method',
linetype = 'Classification Method',
shape = 'Classification Method') +
theme(legend.position = 'right',
plot.margin = unit(c(0.1, 0.7, 0.3, 0.3), "cm"),
panel.grid.minor.x = element_blank()) +
geom_line(data = df_plot_smooth, aes(x = sigma, y = value, col = method,
linetype = method),
linewidth = 0.95) +
scale_colour_manual(values = rep(c('deepskyblue2', 'tomato'), c(4, 4)),
labels = methods_names) +
scale_linetype_manual(values = rep(c('dotdash', 'dashed', 'solid', 'dotted'), 2),
labels = methods_names) +
scale_shape_manual(values = rep(c(16, 1, 17, 4, 16, 1, 17, 4)),
labels = methods_names) +
guides(colour = guide_legend(override.aes = list(size = 1.2, alpha = 0.7)),
linetype = guide_legend(override.aes = list(linewidth = 0.8)))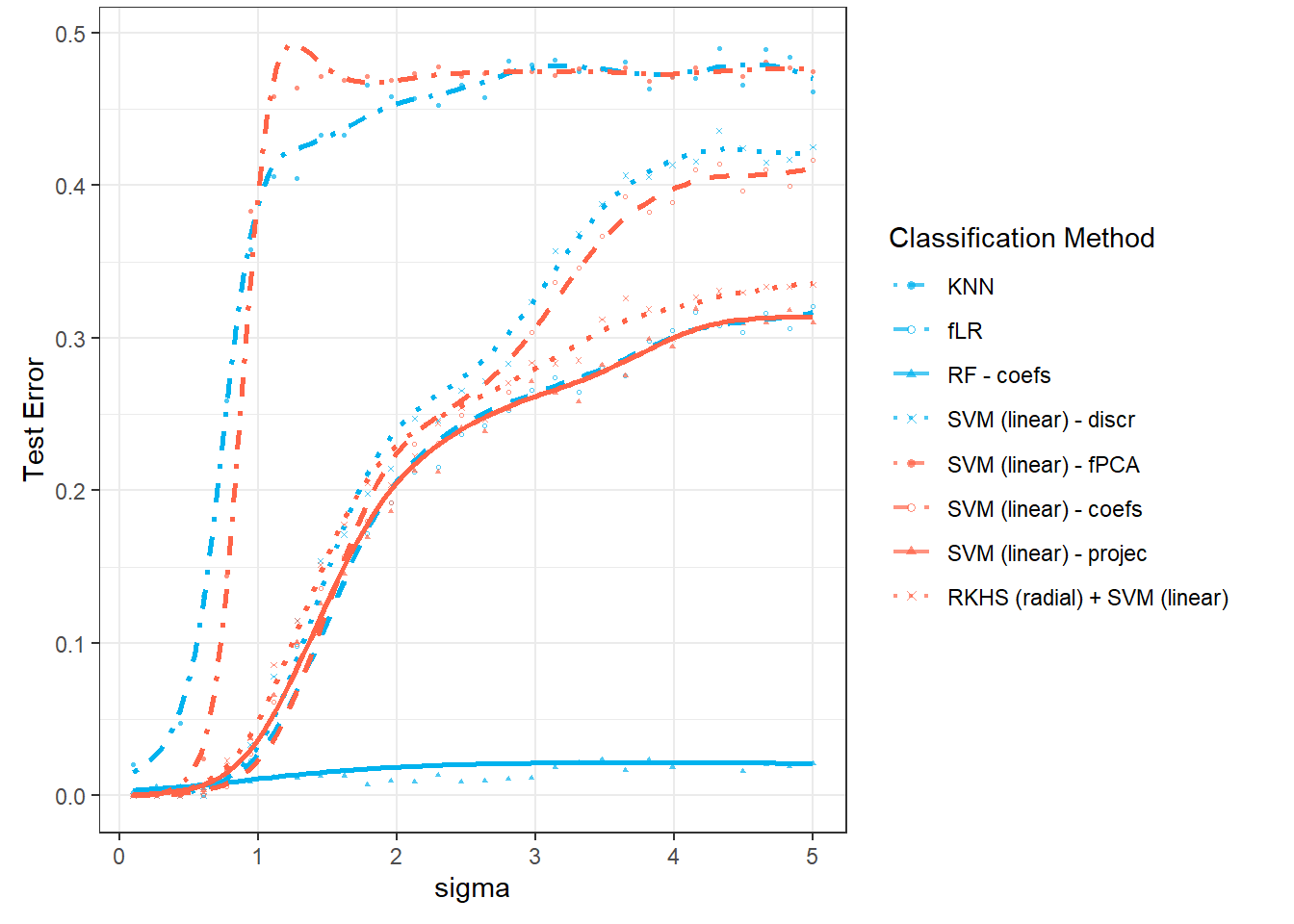
Figure 2.15: Graph of the dependence of test error for individual classification methods on the value of the parameter \(\sigma_{x}\).
Now we will do the same for test error.
Code
methods_subset <- c('KNN', 'LR_functional', 'RF_Bbasis', 'SVM linear - diskr',
'SVM linear - PCA', 'SVM linear - Bbasis',
'SVM linear - projection', 'SVM linear - RKHS - radial')
# methods_subset <- c('KNN', 'LR_functional', 'SVM linear - diskr',
# 'SVM linear - PCA',
# 'SVM linear - projection', 'SVM linear - RKHS - radial')
Dat <- SIMUL_params[, 2, ] |>
as.data.frame() |> t()
breaks <- sigma_vector
rangeval <- range(breaks)
norder <- 4
bbasis <- create.bspline.basis(rangeval = rangeval,
norder = norder,
breaks = breaks)
curv.Lfd <- int2Lfd(2)
# lambda.vect <- 10^seq(from = -2, to = 1, length.out = 50) # vector of lambdas
# gcv <- rep(NA, length = length(lambda.vect)) # empty vector for storing GCV
# for(index in 1:length(lambda.vect)) {
# curv.Fdpar <- fdPar(bbasis, curv.Lfd, lambda.vect[index])
# BSmooth <- smooth.basis(breaks, Dat, curv.Fdpar) # smoothing
# gcv[index] <- mean(BSmooth$gcv) # average over all observed curves
# }
#
# GCV <- data.frame(
# lambda = round(log10(lambda.vect), 3),
# GCV = gcv
# )
#
# # find the minimum value
# lambda.opt <- lambda.vect[which.min(gcv)]
#
# curv.fdPar <- fdPar(bbasis, curv.Lfd, lambda.opt)
# BSmooth <- smooth.basis(breaks, Dat, curv.fdPar) # smooth.pos
# XXfd <- BSmooth$fd # Wfdobj
#
# fdobjSmootheval <- eval.fd(fdobj = XXfd, # eval.posfd
# evalarg = seq(min(sigma_vector), max(sigma_vector),
# length = 101))
# df_plot_smooth <- data.frame(
# method = rep(colnames(fdobjSmootheval), each = dim(fdobjSmootheval)[1]),
# value = c(fdobjSmootheval),
# sigma = rep(seq(min(sigma_vector), max(sigma_vector), length = 101), length(methods))
# ) |>
# mutate(method = factor(method, levels = methods, labels = methods, ordered = TRUE))
## for positive smoothing
# find the minimum value
lambda.opt <- 3e-4
curv.fdPar <- fdPar(bbasis, curv.Lfd, lambda.opt)
BSmooth <- smooth.pos(breaks, Dat, curv.fdPar, dbglev = 0,
# wtvec = c(rep(1000, 5), rep(100, 5), rep(1, 20))
wtvec = c(rep(1000, 5), seq(100, 10, length = 5), rep(1, 20))
) # smooth.posCode
XXfd <- BSmooth$Wfdobj # Wfdobj
fdobjSmootheval <- eval.posfd(Wfdobj = XXfd, # eval.posfd
evalarg = seq(min(sigma_vector), max(sigma_vector),
length = 101))
df_plot_smooth <- data.frame(
method = rep(methods, each = dim(fdobjSmootheval)[1]),
value = c(fdobjSmootheval),
sigma = rep(seq(min(sigma_vector), max(sigma_vector), length = 101), length(methods))
) |>
filter(method %in% methods_subset) |>
mutate(method = factor(method, levels = methods_subset,
labels = methods_subset, ordered = TRUE)) Code
# for test data
SIMUL_params[, 2, ] |>
as.data.frame() |>
mutate(method = methods) |>
pivot_longer(cols = as.character(sigma_vector),
names_to = 'sigma',
values_to = 'Err') |>
mutate(method = factor(method, levels = methods, labels = methods, ordered = TRUE),
sigma = as.numeric(sigma)) |>
# filter(method %in% c('KNN', 'QDA', 'LR_functional',
# 'RF_discr', #'RF_score', 'RF_Bbasis',
# 'SVM linear - diskr',# 'SVM poly - diskr', 'SVM rbf - diskr',
# # 'SVM linear - PCA',# 'SVM poly - PCA', 'SVM rbf - PCA',
# 'SVM linear - Bbasis',# 'SVM poly - Bbasis', 'SVM rbf - Bbasis',
# 'SVM linear - projection',# 'SVM poly - projection',
# # 'SVM rbf - projection',
# 'SVM linear - RKHS - radial'#, 'SVM poly - RKHS - radial',
# # 'SVM rbf - RKHS - radial'
# )) |>
filter(method %in% methods_subset) |>
mutate(method = factor(method, levels = methods_subset,
labels = methods_subset, ordered = TRUE)) |>
ggplot(aes(x = sigma, y = Err, colour = method, shape = method)) +
geom_point(alpha = 0.7, size = 0.6) +
theme_bw() +
# facet_wrap(~factor(param, c('sigma', 'shift'))) +
labs(x = 'sigma',
y = 'Test Error',
colour = 'Classification Method',
linetype = 'Classification Method',
shape = 'Classification Method') +
theme(legend.position = 'right',
plot.margin = unit(c(0.1, 0.5, 0.3, 0.3), "cm"),
panel.grid.minor.x = element_blank(),
strip.background = element_blank(),
strip.text.x = element_blank()) +
# guides(colour=guide_legend(direction = 'vertical'),
# linetype=guide_legend(direction = 'vertical'),
# shape=guide_legend(direction = 'vertical')) +
# scale_y_log10() +
geom_line(data = df_plot_smooth, aes(x = sigma, y = value, col = method,
linetype = method),
linewidth = 1.5) +
scale_colour_manual(values = rep(c('deepskyblue2', 'tomato'), c(4, 4)),
labels = methods_names) +
scale_linetype_manual(values = rep(c('dotdash', 'dashed', 'solid', 'dotted'), 2),
labels = methods_names) +
scale_shape_manual(values = rep(c(16, 1, 17, 4, 16, 1, 17, 4)),
labels = methods_names) +
guides(colour = guide_legend(override.aes = list(size = 1.4, alpha = 0.6)),
linetype = guide_legend(override.aes = list(linewidth = 0.7)))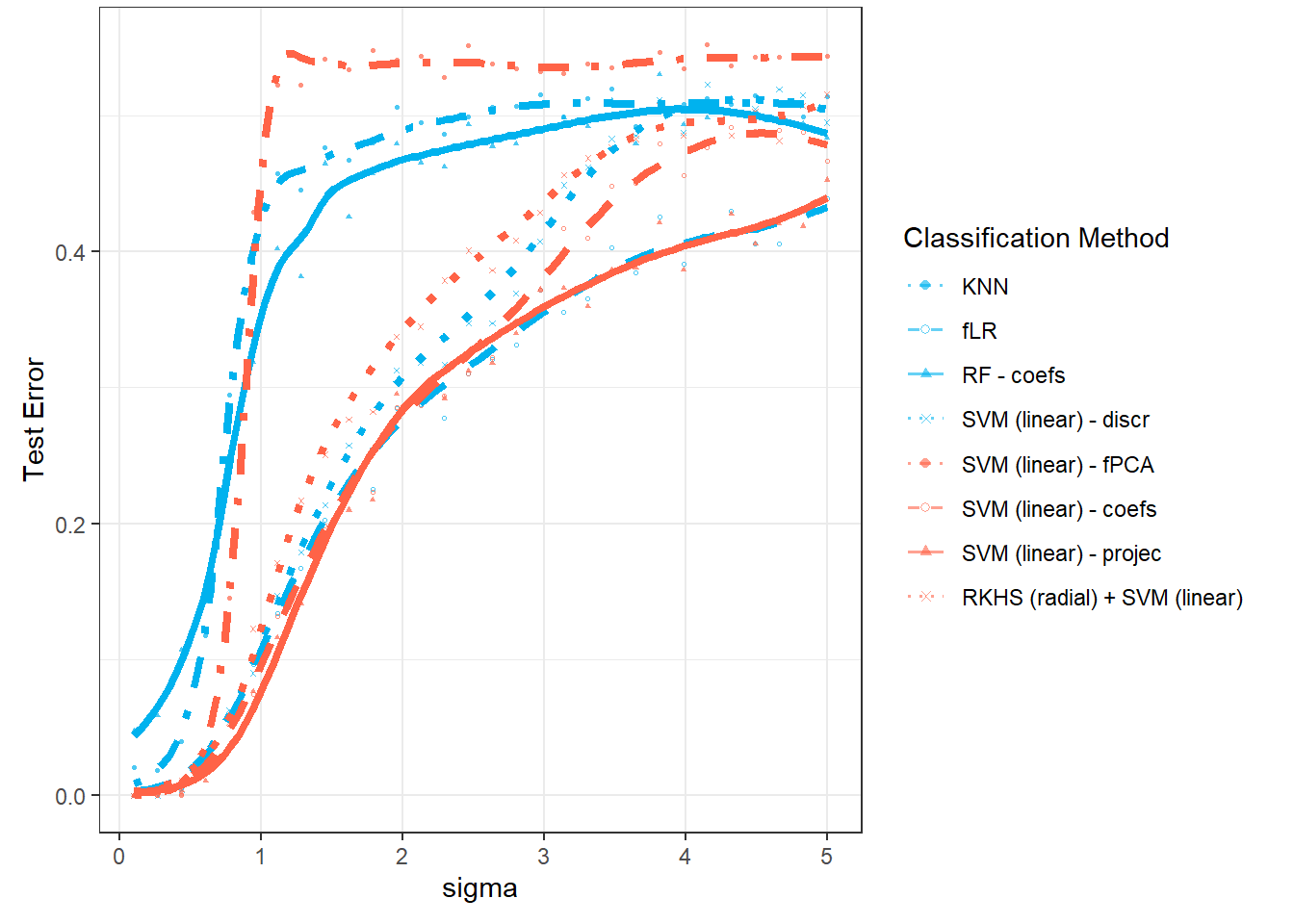
Figure 2.16: Graph of the dependence of test error for individual classification methods on the parameter \(\sigma_{x}\).
Comments on the graphs can be found in the thesis. We only note that as the value of \(\sigma\) increases, the test error also increases for all methods. Functional logistic regression and projection onto the B-spline basis combined with the SVM method with a linear kernel perform the best.